
Crawler e il loro ruolo nel posizionamento sui motori di ricerca
I crawler accumulano dati e informazioni da Internet visitando siti web e leggendo le pagine. Scopri di più su di loro.
6 min di lettura
SEO
Crawlers
+4
Scopri come identificare i crawler dei motori di ricerca utilizzando stringhe user-agent, indirizzi IP, pattern di richiesta e analisi comportamentale. Guida essenziale per webmaster e sviluppatori.
I crawler dei motori di ricerca possono essere identificati attraverso quattro metodi principali: analizzando la stringa user-agent nell’header HTTP, verificando l’indirizzo IP di origine e l’hostname DNS inverso, monitorando i pattern di richiesta per accessi ad alta frequenza ed esaminando le caratteristiche comportamentali come la capacità di eseguire JavaScript.
I crawler dei motori di ricerca sono programmi automatici che navigano sistematicamente in Internet per scoprire, analizzare e indicizzare i contenuti web. Identificare questi crawler è fondamentale per webmaster, sviluppatori e marketer affiliati che devono comprendere i pattern di traffico sul proprio sito e garantire l’accesso legittimo dei motori di ricerca. A differenza dei bot malevoli che cercano di estrarre dati o lanciare attacchi, i crawler legittimi come Googlebot, Bingbot e altri si identificano tramite marker tecnici specifici che possono essere verificati e autenticati.
La capacità di distinguere tra crawler dei motori di ricerca legittimi e altri tipi di bot è diventata sempre più importante nel 2025, man mano che il traffico web cresce e l’attività dei bot diventa più sofisticata. Comprendere i metodi di identificazione ti aiuta a ottimizzare la crawlabilità del sito, proteggere le risorse da accessi non autorizzati e assicurare che i sistemi di tracciamento delle affiliazioni distinguano con precisione tra traffico organico da ricerca e altre fonti. PostAffiliatePro offre funzionalità di analisi avanzate che ti aiutano a monitorare e categorizzare le fonti di traffico in modo accurato, assicurando che il tuo programma di affiliazione raccolga dati di performance precisi.
Il metodo più diretto per identificare i crawler dei motori di ricerca consiste nell’esaminare la stringa User-Agent nell’header delle richieste HTTP. Ogni richiesta HTTP include un header User-Agent che identifica il client che effettua la richiesta, che sia un browser web, un’app mobile o un crawler. I crawler legittimi includono identificativi distintivi nelle loro stringhe User-Agent che indicano chiaramente la loro origine e finalità. Ad esempio, il crawler di Google si identifica come “Googlebot/2.1 (+http://www.google.com/bot.html)”, mentre il crawler di Microsoft Bing utilizza “Bingbot/2.0 (+http://www.bing.com/bingbot.htm)”.
Quando analizzi le stringhe User-Agent, dovresti cercare pattern e parole chiave specifiche che indichino crawler dei motori di ricerca legittimi. La stringa User-Agent solitamente contiene il nome del crawler, la versione e un link alla documentazione o pagina informativa del crawler. I crawler legittimi dei principali motori di ricerca come Google, Bing, Yahoo e Yandex seguono convenzioni di denominazione coerenti e includono informazioni verificabili sul loro scopo. Puoi registrare queste stringhe User-Agent nei log di accesso del server e confrontarle con gli identificatori noti dei crawler mantenuti da motori di ricerca e organizzazioni di sicurezza.
| Nome Crawler | Esempio Stringa User-Agent | Motore di Ricerca |
|---|---|---|
| Googlebot | Googlebot/2.1 (+http://www.google.com/bot.html) | |
| Bingbot | Bingbot/2.0 (+http://www.bing.com/bingbot.htm) | Microsoft Bing |
| Slurp | Slurp/cat (+http://help.yahoo.com/help/us/ysearch/slurp) | Yahoo |
| Yandexbot | Mozilla/5.0 (compatible; YandexBot/3.0) | Yandex |
| DuckDuckBot | DuckDuckBot/1.0 (+http://duckduckgo.com/duckduckbot.html) | DuckDuckGo |
Tuttavia, affidarsi solamente alle stringhe User-Agent per identificare i crawler presenta dei limiti. I bot malevoli possono falsificare le stringhe User-Agent per impersonare crawler legittimi, rendendo essenziale combinare questo metodo con ulteriori tecniche di verifica. Inoltre, alcuni crawler legittimi potrebbero utilizzare stringhe User-Agent generiche o modificate in determinate situazioni, quindi il confronto incrociato con altri metodi di identificazione offre risultati più affidabili.
Configura il tracciamento avanzato in pochi minuti. Nessuna carta di credito richiesta.
Il secondo metodo fondamentale per identificare i crawler dei motori di ricerca riguarda la verifica dell’indirizzo IP di origine e l’esecuzione di un reverse DNS lookup. Quando un crawler effettua una richiesta al tuo server, proviene da un indirizzo IP specifico che può essere registrato e analizzato. I motori di ricerca pubblicano gli intervalli di indirizzi IP utilizzati dai loro crawler, consentendo ai webmaster di verificare se una richiesta proviene realmente dall’infrastruttura di quel motore di ricerca. Google, ad esempio, mantiene un elenco completo degli indirizzi IP utilizzati da Googlebot e altri crawler di Google.
Il reverse DNS lookup è una tecnica di verifica particolarmente efficace che consiste nell’interrogare il sistema DNS per determinare l’hostname associato a un indirizzo IP. Se effettui un reverse DNS lookup su un IP che dichiara di essere di Google, dovrebbe restituire un hostname all’interno del dominio Google (come “crawl-66-249-64-1.googlebot.com”). Questo hostname può poi essere verificato tramite un forward DNS lookup, per confermare che l’hostname risolva allo stesso indirizzo IP, creando una catena di verifica bidirezionale. Questo processo rende estremamente difficile per attori malevoli falsificare l’identità del crawler, poiché dovrebbero controllare sia l’indirizzo IP sia i relativi record DNS.
La documentazione ufficiale di Google raccomanda questo metodo come il più affidabile per confermare le richieste di Googlebot. Il processo prevede di verificare che l’hostname DNS inverso corrisponda al pattern di dominio di Google e che una successiva risoluzione DNS diretta dell’hostname restituisca lo stesso indirizzo IP. Questo metodo è particolarmente prezioso per siti ad alto traffico e reti di affiliazione che necessitano di attribuzione accurata del traffico e di prevenire che attività di bot fraudolenti vengano conteggiate come traffico legittimo dei motori di ricerca.
L’analisi dei pattern di richiesta offre preziose informazioni sul comportamento dei crawler, esaminando come le richieste vengono distribuite nel tempo e sulle risorse del sito. I crawler dei motori di ricerca legittimi seguono pattern prevedibili che differiscono notevolmente dal comportamento umano o dall’attività dei bot malevoli. Tipicamente, i crawler effettuano richieste a intervalli regolari, seguono una navigazione logica attraverso la struttura degli URL del sito e rispettano le direttive specificate nel file robots.txt. Monitorando questi pattern, puoi identificare i crawler legittimi e distinguerli da attività sospette.
Quando analizzi i pattern di richiesta, cerca alcune caratteristiche chiave che indicano un comportamento tipico dei crawler. Per prima cosa, esamina la frequenza e la distribuzione delle richieste: i crawler legittimi tendono a distanziare le richieste per evitare di sovraccaricare il server, spesso seguendo algoritmi di backoff esponenziale che rallentano se ricevono errori HTTP 500 o altri segnali di stress del server. Secondo, analizza il pattern di navigazione degli URL: i crawler legittimi seguono sistematicamente i link e rispettano la struttura del sito, mentre i bot malevoli spesso effettuano richieste casuali o sequenziali a URL inesistenti o non collegati dal sito. Terzo, monitora i tipi di risorse richieste: i crawler legittimi richiedono solitamente pagine HTML, file CSS e JavaScript necessari per il rendering, evitando richieste inutili a file binari o directory sensibili.
Puoi implementare il monitoraggio dei pattern di richiesta analizzando i log del server e identificando cluster di richieste con caratteristiche comuni. Strumenti come piattaforme di web analytics e software di analisi dei log del server possono automatizzare questo processo segnalando pattern anomali. Ad esempio, se un singolo indirizzo IP effettua 1.000 richieste al minuto a diverse pagine prodotto in sequenza, probabilmente si tratta di un crawler. Al contrario, i crawler legittimi solitamente effettuano richieste a una frequenza molto più bassa, distanziando di diversi secondi le richieste per rispettare le risorse del server ed evitare il rate limiting.
Sii il primo a conoscere le nuove funzionalità e gli aggiornamenti del prodotto.
L’analisi comportamentale esamina come i crawler interagiscono con i contenuti e la tecnologia del sito, fornendo indicazioni che distinguono i crawler dei motori di ricerca legittimi da altri tipi di bot. Una delle caratteristiche comportamentali più importanti è la capacità di eseguire JavaScript. I motori di ricerca moderni come Google renderizzano le pagine utilizzando un browser headless (simile a Chrome) per eseguire JavaScript e accedere ai contenuti generati dinamicamente. Questo significa che i crawler legittimi eseguiranno il codice JavaScript sulle tue pagine, mentre molti bot malevoli o scraper semplici non sono in grado di farlo o non lo eseguono affatto.
Puoi rilevare l’esecuzione di JavaScript inserendo codice di tracciamento che si attiva solo quando JavaScript è abilitato e funzionante. Se una richiesta accede alla tua pagina ma non attiva il tracciamento dipendente da JavaScript o non carica contenuti generati dinamicamente, è probabile che il richiedente non sia un moderno crawler dei motori di ricerca. Inoltre, i crawler legittimi caricano tutte le risorse necessarie per il rendering completo di una pagina, inclusi immagini, fogli di stile e file JavaScript, mentre i bot semplici potrebbero richiedere solo il file HTML senza caricare le risorse di supporto.
Un altro indicatore comportamentale importante è il modo in cui i crawler gestiscono elementi interattivi e invii di form. I crawler dei motori di ricerca legittimi non inviano form, non cliccano bottoni e non interagiscono con i contenuti dinamici in modi che possano generare effetti indesiderati come ordini o modifiche ai dati. Si concentrano sulla lettura e analisi dei contenuti, piuttosto che sull’interazione. Al contrario, i bot malevoli spesso tentano di interagire con i form, inviare dati o attivare azioni che potrebbero danneggiare il sito o rubare informazioni. Monitorando questi pattern comportamentali, puoi identificare le richieste che tentano interazioni non autorizzate e distinguerle dall’attività dei crawler legittimi.
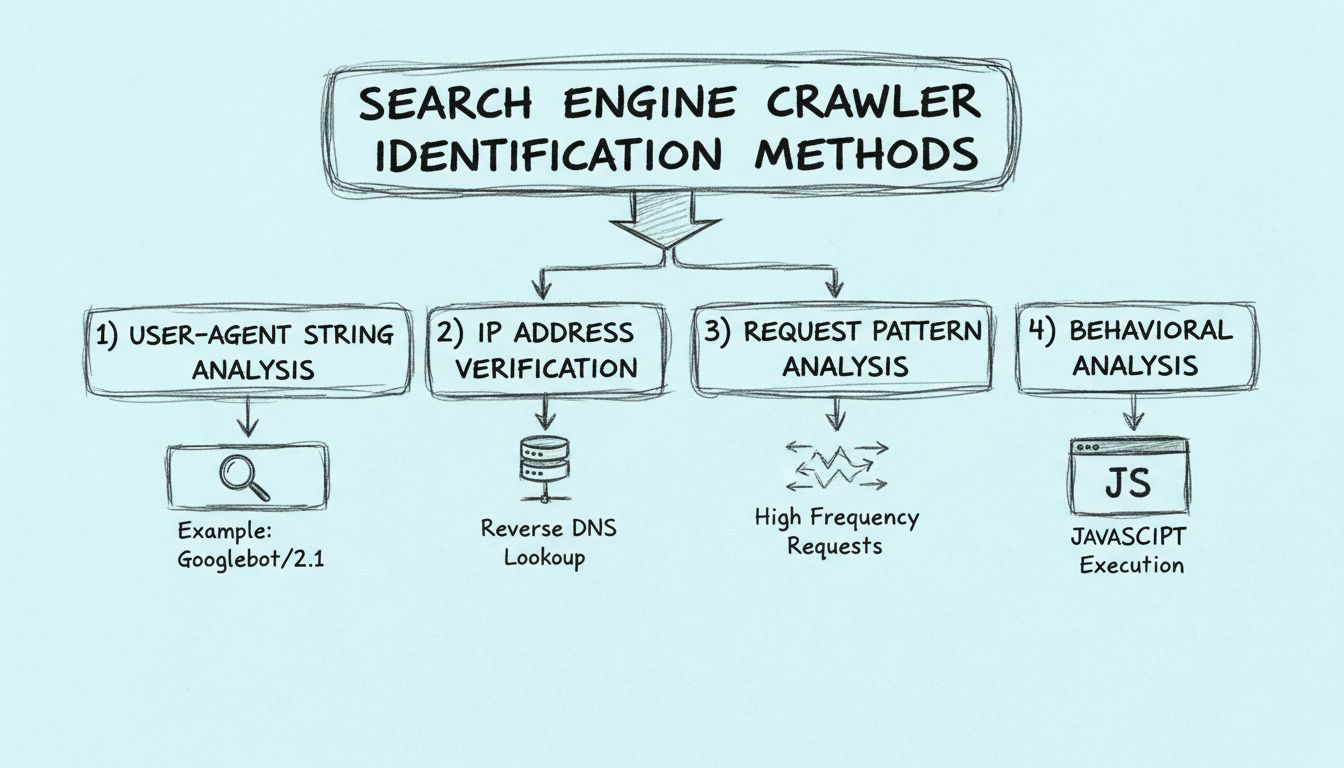
L’approccio più efficace all’identificazione dei crawler combina tutti e quattro i metodi in un workflow di verifica completo. Invece di affidarti a un solo metodo, implementare un sistema di verifica a più livelli offre una protezione robusta contro i crawler falsificati e garantisce un’attribuzione accurata del traffico. Inizia registrando la stringa User-Agent e l’indirizzo IP di ogni richiesta, quindi confrontali con i database di crawler noti mantenuti da motori di ricerca e organizzazioni di sicurezza. Successivamente, esegui un reverse DNS lookup per verificare che l’hostname dell’indirizzo IP corrisponda al dominio del motore di ricerca dichiarato. Infine, analizza il pattern delle richieste e le caratteristiche comportamentali per assicurarti che l’attività sia coerente con un crawler legittimo.
Questo approccio multilivello è particolarmente importante per le reti di affiliazione e le piattaforme di performance marketing come PostAffiliatePro, dove un’attribuzione accurata del traffico incide direttamente sul calcolo delle commissioni e sull’integrità del programma. Implementando un’identificazione completa dei crawler, puoi assicurarti che i sistemi di tracciamento delle affiliazioni distinguano con precisione tra traffico legittimo dai motori di ricerca, traffico pubblicitario e traffico organico degli utenti. Questa precisione consente analisi delle performance migliori, calcoli ROI più accurati e capacità di rilevamento delle frodi migliorate.
Le infrastrutture web moderne richiedono sistemi sofisticati di identificazione dei crawler in grado di gestire la complessità del traffico web contemporaneo. Innanzitutto, mantieni un elenco aggiornato degli indirizzi IP e delle stringhe User-Agent dei crawler legittimi iscrivendoti alle notifiche ufficiali dei principali motori di ricerca. Google, Bing e altri motori di ricerca pubblicano aggiornamenti quando introducono nuovi crawler o modificano la loro infrastruttura, e rimanere informati su questi cambiamenti garantisce che i tuoi sistemi di identificazione restino attuali. In secondo luogo, implementa un sistema di logging lato server che registri tutti i metadati rilevanti delle richieste, incluse le stringhe User-Agent, indirizzi IP, timestamp e risorse richieste. Questi dati costituiscono la base per l’analisi dei pattern e il monitoraggio comportamentale.
In terzo luogo, valuta l’implementazione di un’API o servizio di verifica dei crawler che validi automaticamente l’identità dei crawler in tempo reale. Molte piattaforme di sicurezza e analisi offrono ora servizi di identificazione dei crawler che mantengono database aggiornati dei crawler legittimi e possono verificare le richieste rispetto a questi database. In quarto luogo, stabilisci policy chiare per la gestione delle attività di crawler non identificati o sospetti. Potresti scegliere di servire normalmente tali richieste registrandole per analisi, oppure implementare rate limiting per prevenire l’esaurimento delle risorse. Infine, rivedi e aggiorna regolarmente le regole e le soglie di identificazione dei crawler in base ai pattern di traffico osservati e alle minacce emergenti. Il panorama del crawling web continua a evolversi e i tuoi sistemi di identificazione dovrebbero adattarsi di conseguenza per mantenere la loro efficacia.
Identificare i crawler dei motori di ricerca richiede una comprensione approfondita di molteplici metodi di verifica e la capacità di combinarli in un sistema di rilevamento efficace. Analizzando le stringhe User-Agent, verificando gli indirizzi IP tramite DNS inversi, monitorando i pattern di richiesta ed esaminando le caratteristiche comportamentali, puoi distinguere in modo affidabile i crawler legittimi degli engine di ricerca da altri tipi di bot e fonti di traffico. Questa capacità è essenziale per webmaster, sviluppatori e marketer affiliati che devono comprendere le fonti del traffico e garantire un tracciamento delle performance accurato. Le funzionalità avanzate di analisi e monitoraggio del traffico di PostAffiliatePro ti aiutano a implementare efficacemente questi metodi di identificazione, assicurando che il tuo programma di affiliazione raccolga dati precisi e mantenga l’integrità in un panorama digitale sempre più complesso.
PostAffiliatePro è il principale software di gestione affiliati che ti aiuta a tracciare, gestire e ottimizzare la tua rete di affiliati con precisione. Identifica le fonti di traffico legittime e massimizza le performance del tuo programma di affiliazione con analisi avanzate e monitoraggio in tempo reale.
I crawler accumulano dati e informazioni da Internet visitando siti web e leggendo le pagine. Scopri di più su di loro.
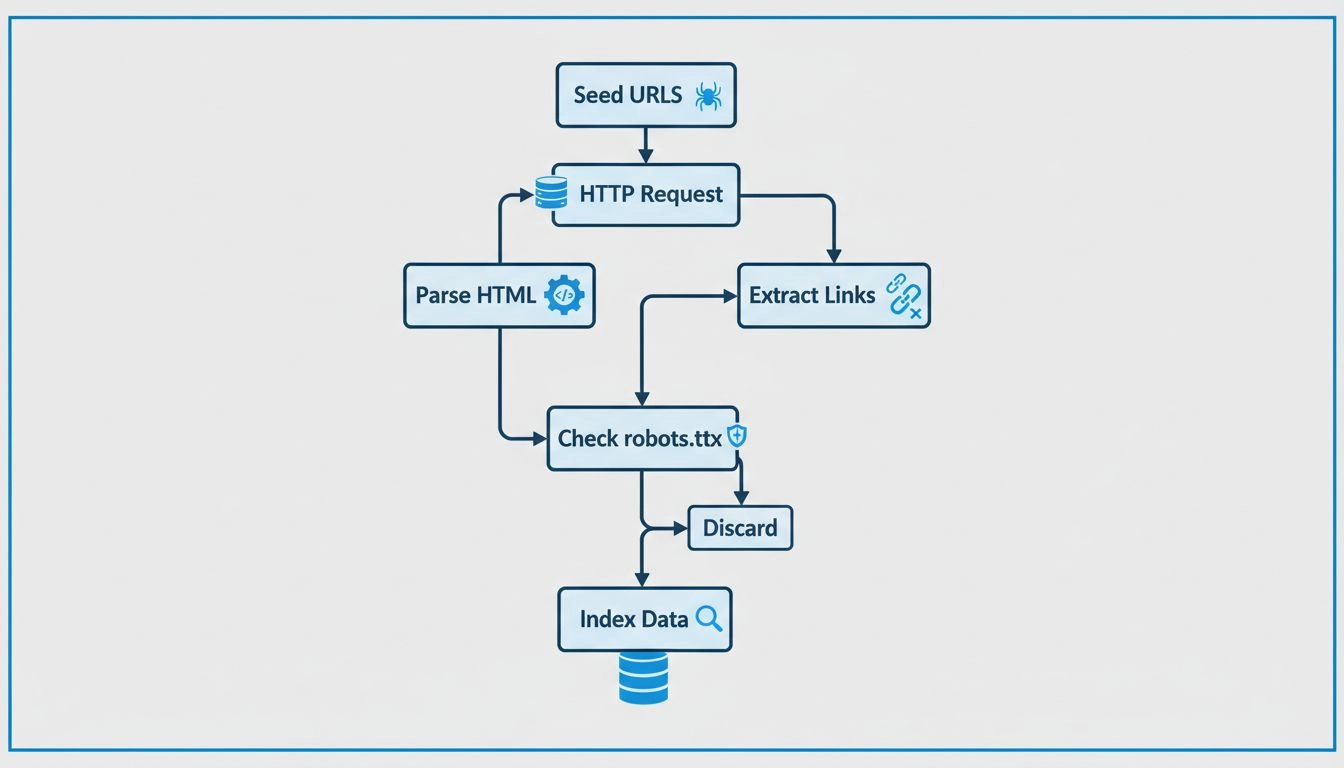
Scopri come funzionano i web crawler, dagli URL seed all'indicizzazione. Comprendi il processo tecnico, i tipi di crawler, le regole del robots.txt e come i cra...
Un motore di ricerca è un software creato per rendere più facile la ricerca su Internet agli utenti. Esamina milioni di pagine e fornisce i risultati più rileva...
Unisciti alla nostra community di clienti soddisfatti e fornisci un eccellente supporto clienti con PostAffiliatePro.
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.