
Crawler e il loro ruolo nel posizionamento sui motori di ricerca
I crawler accumulano dati e informazioni da Internet visitando siti web e leggendo le pagine. Scopri di più su di loro.
6 min di lettura
SEO
Crawlers
+4
Scopri come funzionano i web crawler, dagli URL seed all’indicizzazione. Comprendi il processo tecnico, i tipi di crawler, le regole del robots.txt e come i crawler influenzano la SEO e il marketing di affiliazione.
I web crawler funzionano inviando richieste HTTP ai siti web a partire dagli URL seed, seguendo i collegamenti ipertestuali per scoprire nuove pagine, analizzando il contenuto HTML per estrarre informazioni, rispettando le regole del robots.txt e memorizzando i dati raccolti in indici ricercabili. Visitano sistematicamente le pagine, estraggono metadati e link, e ripetono il processo per mantenere aggiornati i database dei motori di ricerca.
I web crawler, noti anche come spider o bot, sono programmi automatizzati che navigano sistematicamente in internet per scoprire, scaricare e analizzare i contenuti web. Questi agenti intelligenti costituiscono la spina dorsale dell’infrastruttura dei motori di ricerca, permettendo a piattaforme come Google, Bing e altri servizi di ricerca di costruire indici completi di miliardi di pagine web. Lo scopo principale dei web crawler è raccogliere e organizzare informazioni dai siti, così che i motori di ricerca possano recuperare rapidamente i risultati più pertinenti quando gli utenti effettuano ricerche. Senza i web crawler, i motori di ricerca non avrebbero modo di scoprire nuovi contenuti o mantenere aggiornati i loro indici con le ultime informazioni disponibili online.
L’importanza dei web crawler va ben oltre la semplice funzione di ricerca. Sono la base per numerose applicazioni digitali, tra cui siti di comparazione prezzi, aggregatori di contenuti, piattaforme di ricerca di mercato, strumenti di analisi SEO e servizi di archiviazione web. Per i marketer di affiliazione e gli operatori di network come quelli che utilizzano PostAffiliatePro, capire come funzionano i crawler è essenziale per assicurarsi che i contenuti di affiliazione, le pagine prodotto e i materiali promozionali vengano scoperti e indicizzati correttamente dai motori di ricerca. Questa visibilità influisce direttamente sul traffico organico, sulla generazione di lead e, in definitiva, sulle opportunità di commissione per gli affiliati.
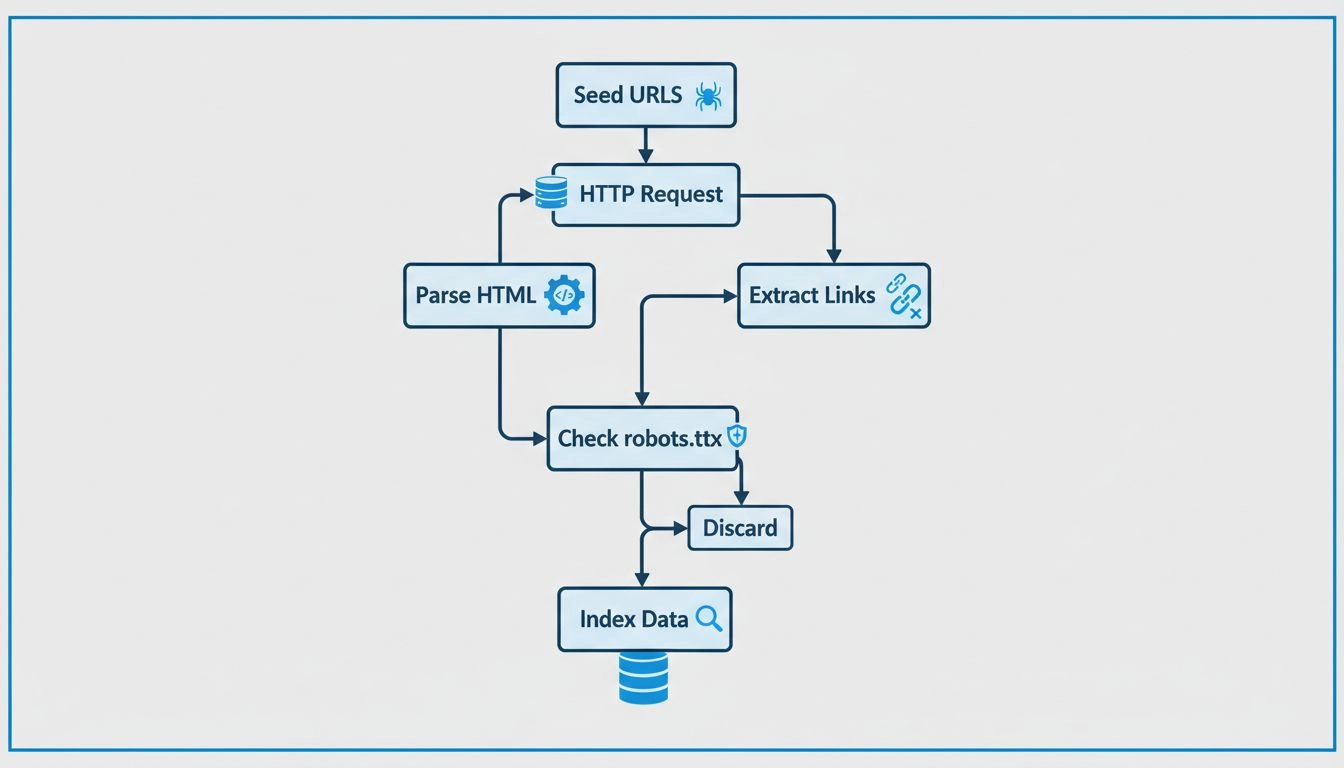
I web crawler seguono un processo metodico e strutturato per esplorare sistematicamente il web. Il processo inizia con gli URL seed, ovvero punti di partenza conosciuti come URL delle homepage, sitemap XML o pagine precedentemente scansionate. Questi URL seed fungono da punto d’ingresso per il viaggio del crawler attraverso il web. Il crawler mantiene una coda di URL da visitare, spesso chiamata “crawl frontier”, che cresce continuamente man mano che vengono scoperti nuovi link durante il processo di crawling.
Quando un crawler raggiunge un URL, invia una richiesta HTTP al server web che ospita quella pagina. Il server risponde inviando il contenuto HTML della pagina, in modo simile a come un browser carica una pagina quando la visiti. Il crawler quindi analizza questo codice HTML per estrarre informazioni preziose, tra cui il testo della pagina, i meta tag (come titolo e descrizione), immagini, video e, soprattutto, i collegamenti ad altre pagine. L’estrazione dei link è fondamentale perché consente al crawler di scoprire nuovi URL non ancora visitati, che vengono quindi aggiunti alla coda per future visite.
| Fase del Processo del Crawler | Descrizione | Azioni Chiave |
|---|---|---|
| Inizializzazione | Avvio del processo di crawling | Carica gli URL seed, inizializza la coda di crawling |
| Richiesta & Recupero | Recupero dei contenuti della pagina | Invia richieste HTTP, riceve risposte HTML |
| Analisi HTML | Analisi della struttura della pagina | Estrae testo, metadati, link, media |
| Estrazione Link | Ricerca di nuovi URL | Identifica link ipertestuali, aggiunge alla coda |
| Controllo robots.txt | Rispetto delle regole del sito | Verifica i permessi di crawling prima della visita |
| Memorizzazione Contenuto | Salvataggio delle informazioni | Indicizza i dati in un database ricercabile |
| Prioritizzazione | Determina le prossime pagine | Classifica gli URL per importanza e rilevanza |
| Ripetizione | Continua il ciclo | Processa il prossimo URL in coda |
Prima di visitare un nuovo URL su un dominio, i crawler responsabili controllano il file robots.txt situato nella directory principale di quel dominio. Questo file contiene istruzioni che i proprietari dei siti utilizzano per comunicare ai crawler quali pagine possono essere scansionate e quali devono essere evitate. Ad esempio, un proprietario di sito può usare robots.txt per impedire ai crawler di accedere a pagine sensibili, contenuti duplicati o sezioni pesanti che potrebbero sovraccaricare i loro server. La maggior parte dei crawler legittimi dei motori di ricerca rispetta queste istruzioni per mantenere buoni rapporti con i proprietari dei siti ed evitare problemi di performance.
Configura il tracciamento avanzato in pochi minuti. Nessuna carta di credito richiesta.
I web crawler moderni si sono evoluti notevolmente per gestire la complessità dei siti web contemporanei. Molti siti oggi utilizzano JavaScript per generare contenuti dinamicamente dopo il caricamento della pagina, il che significa che la risposta HTML iniziale non contiene tutto il contenuto. I crawler avanzati ora utilizzano browser headless per eseguire JavaScript e catturare contenuti caricati dinamicamente che non sarebbero visibili ai crawler tradizionali. Questa capacità è essenziale per la scansione di single-page application, dashboard interattivi e applicazioni web moderne che si basano fortemente sul rendering lato client.
I crawler implementano sofisticati algoritmi di prioritizzazione per utilizzare in modo efficiente il loro budget di crawling—il numero limitato di pagine che possono scansionare in un determinato periodo. Questi algoritmi considerano diversi fattori, tra cui l’autorità della pagina (determinata dalla qualità e quantità dei backlink), la struttura dei link interni, la freschezza dei contenuti, il volume di traffico e la reputazione del dominio. Le pagine di maggiore autorità e i contenuti aggiornati frequentemente ricevono visite più frequenti, mentre le pagine meno importanti o statiche possono essere visitate meno spesso o saltate. Questa prioritizzazione intelligente assicura che i crawler concentrino le risorse sui contenuti più preziosi e frequentemente aggiornati.
Crawl delay e rate limiting sono meccanismi importanti che impediscono ai crawler di sovraccaricare i server web. I crawler responsabili implementano pause tra le richieste e rispettano le direttive di crawl-delay specificate nei file robots.txt. Questo comportamento educato salvaguarda le prestazioni e l’esperienza utente, assicurando che il traffico dei crawler non consumi risorse eccessive del server. I siti che caricano lentamente o restituiscono errori possono ricevere una frequenza di scansione ridotta, poiché i crawler rallentano automaticamente per evitare problemi.
Diverse tipologie di web crawler servono a scopi distinti nell’ecosistema digitale. I crawler generali sono utilizzati dai principali motori di ricerca per scansionare l’intero web indiscriminatamente, creando indici completi che alimentano i risultati di ricerca. Questi crawler sono progettati per la massima copertura e operano in modo continuo per scoprire nuovi contenuti e aggiornare gli indici esistenti. I crawler verticali o specializzati si concentrano su settori o tipi di contenuto specifici, come i crawler di offerte di lavoro che cercano nei portali di annunci, i crawler di comparazione prezzi che raccolgono dati da siti e-commerce o i crawler di ricerca che indicizzano articoli accademici e pubblicazioni scientifiche.
I crawler incrementali sono specializzati nell’efficienza, focalizzandosi solo su contenuti nuovi o recentemente modificati invece di scansionare ripetutamente interi siti. Questo approccio riduce notevolmente il carico sui server e il consumo di banda pur mantenendo gli indici abbastanza aggiornati. I crawler focalizzati utilizzano algoritmi sofisticati per cercare contenuti su argomenti o parole chiave specifiche, prioritizzando intelligentemente le pagine che probabilmente contengono informazioni rilevanti. I crawler in tempo reale monitorano costantemente i siti e aggiornano i dati raccolti in tempo reale o quasi, risultando ideali per aggregatori di notizie e applicazioni di monitoraggio dei social media.
I crawler paralleli e i crawler distribuiti rappresentano l’estremità più infrastrutturale dello spettro. I crawler paralleli funzionano su più macchine o thread simultaneamente, aumentando drasticamente la velocità e la capacità di scansione. I crawler distribuiti suddividono il carico su più server o data center, consentendo di processare enormi quantità di dati in modo efficiente. I grandi motori di ricerca come Google utilizzano architetture di crawler distribuiti per gestire i miliardi di pagine presenti su internet.
Sii il primo a conoscere le nuove funzionalità e gli aggiornamenti del prodotto.
I web crawler svolgono un ruolo fondamentale nella SEO perché determinano quali pagine vengono indicizzate e come i motori di ricerca comprendono i tuoi contenuti. Se i crawler non possono accedere alle tue pagine, queste non appariranno nei risultati di ricerca indipendentemente dalla loro qualità o rilevanza. Problemi comuni di crawling che impediscono una corretta indicizzazione includono pagine bloccate da direttive robots.txt, link interni non funzionanti che portano a errori 404, tempi di caricamento lenti che causano timeout dei crawler e problemi di rendering JavaScript che impediscono ai crawler di visualizzare contenuti generati dinamicamente.
I proprietari di siti possono ottimizzare l’accesso dei crawler attraverso diverse strategie chiave. Una struttura del sito chiara con gerarchie di navigazione logiche aiuta i crawler a comprendere le relazioni tra le pagine e la loro importanza. Il collegamento interno segnala ai crawler quali pagine sono più importanti e aiuta a distribuire efficacemente il budget di crawling su tutto il sito. Le sitemap XML elencano esplicitamente tutte le pagine importanti, assicurando che i crawler non perdano contenuti anche su siti grandi o complessi. Tempi di caricamento rapidi incoraggiano i crawler a visitare più pagine all’interno del budget assegnato, mentre contenuti freschi e aggiornati regolarmente segnalano che un sito merita visite più frequenti.
Per i marketer di affiliazione che utilizzano piattaforme come PostAffiliatePro, garantire il corretto accesso dei crawler è fondamentale per generare traffico organico verso i contenuti di affiliazione. Quando le tue pagine prodotto affiliate, articoli di comparazione e contenuti promozionali vengono correttamente scansionati e indicizzati, hanno l’opportunità di posizionarsi nei risultati di ricerca e attrarre traffico qualificato. Una scarsa crawlabilità può causare la mancata indicizzazione e una ridotta visibilità delle tue offerte affiliate.
I proprietari di siti dispongono di diversi strumenti per controllare come i crawler interagiscono con i loro siti. Il file robots.txt è lo strumento principale, contenente direttive che specificano quali user-agent (tipi di crawler) possono accedere a quali parti del sito. Un file robots.txt ben configurato può impedire ai crawler di sprecare risorse su contenuti duplicati, ambienti di staging o pagine pesanti, consentendo loro di scansionare liberamente i contenuti importanti. Il meta tag robots appare nell’HTML di una singola pagina e offre un controllo a livello di pagina, permettendo di escludere specifiche pagine dall’indicizzazione o di ignorarne i link.
L’attributo nofollow indica ai crawler di non seguire determinati collegamenti ipertestuali, utile per impedire ai crawler di seguire link verso siti esterni non affidabili o contenuti generati dagli utenti. Questi meccanismi di controllo lavorano insieme per offrire ai proprietari dei siti un controllo granulare sul comportamento dei crawler, mantenendo buoni rapporti con i motori di ricerca. Tuttavia, è importante notare che scraper malevoli e bot aggressivi spesso ignorano completamente queste direttive, motivo per cui talvolta sono necessarie misure di sicurezza aggiuntive come rate limiting e rilevamento bot.
Per gli operatori di network di affiliazione e i marketer, comprendere il comportamento dei crawler ha un impatto diretto sul successo aziendale. I crawler determinano la visibilità delle pagine prodotto affiliate, dei contenuti di comparazione e dei materiali promozionali nei risultati di ricerca. Quando gli utenti di PostAffiliatePro ottimizzano i propri siti affiliate per una corretta scansione, aumentano la probabilità che i propri contenuti vengano scoperti dai motori di ricerca e posizionati per le parole chiave rilevanti. Questa visibilità organica porta traffico qualificato alle offerte affiliate, aumentando le opportunità di conversione e i guadagni da commissioni.
I network di affiliazione beneficiano dell’attività dei crawler in diversi modi. I crawler dei motori di ricerca aiutano a distribuire i contenuti affiliate in tutto il web, aumentando la notorietà e la portata del brand. I crawler consentono anche ai siti di comparazione prezzi e agli aggregatori di contenuti di scoprire e mostrare prodotti affiliati, creando ulteriori fonti di traffico. Tuttavia, i marketer di affiliazione devono anche prestare attenzione ai crawler malevoli e agli scraper che potrebbero copiare i contenuti affiliate o impegnarsi in frodi sui click. Implementare rate limiting, rilevamento bot e misure di protezione dei contenuti aiuta a salvaguardare l’integrità del network di affiliazione consentendo al contempo ai crawler legittimi di operare correttamente.
PostAffiliatePro offre funzionalità di tracciamento e reportistica avanzate che si integrano all’ottimizzazione per i crawler. Garantendo che i tuoi contenuti di affiliazione vengano correttamente scansionati e indicizzati, unito al tracciamento avanzato e alle analisi di PostAffiliatePro, puoi massimizzare la visibilità e la redditività del tuo network di affiliazione. Il tracciamento delle commissioni in tempo reale e i report intelligenti della piattaforma ti aiutano a capire quali canali affiliate generano il traffico più prezioso, consentendoti di ottimizzare di conseguenza la tua strategia di network.
Proprio come i web crawler scoprono e indicizzano sistematicamente i contenuti, PostAffiliatePro traccia e ottimizza sistematicamente le tue relazioni di affiliazione. La nostra piattaforma offre tracciamento in tempo reale, reportistica completa e gestione intelligente delle commissioni per aiutarti a costruire un network di affiliazione di successo.
I crawler accumulano dati e informazioni da Internet visitando siti web e leggendo le pagine. Scopri di più su di loro.
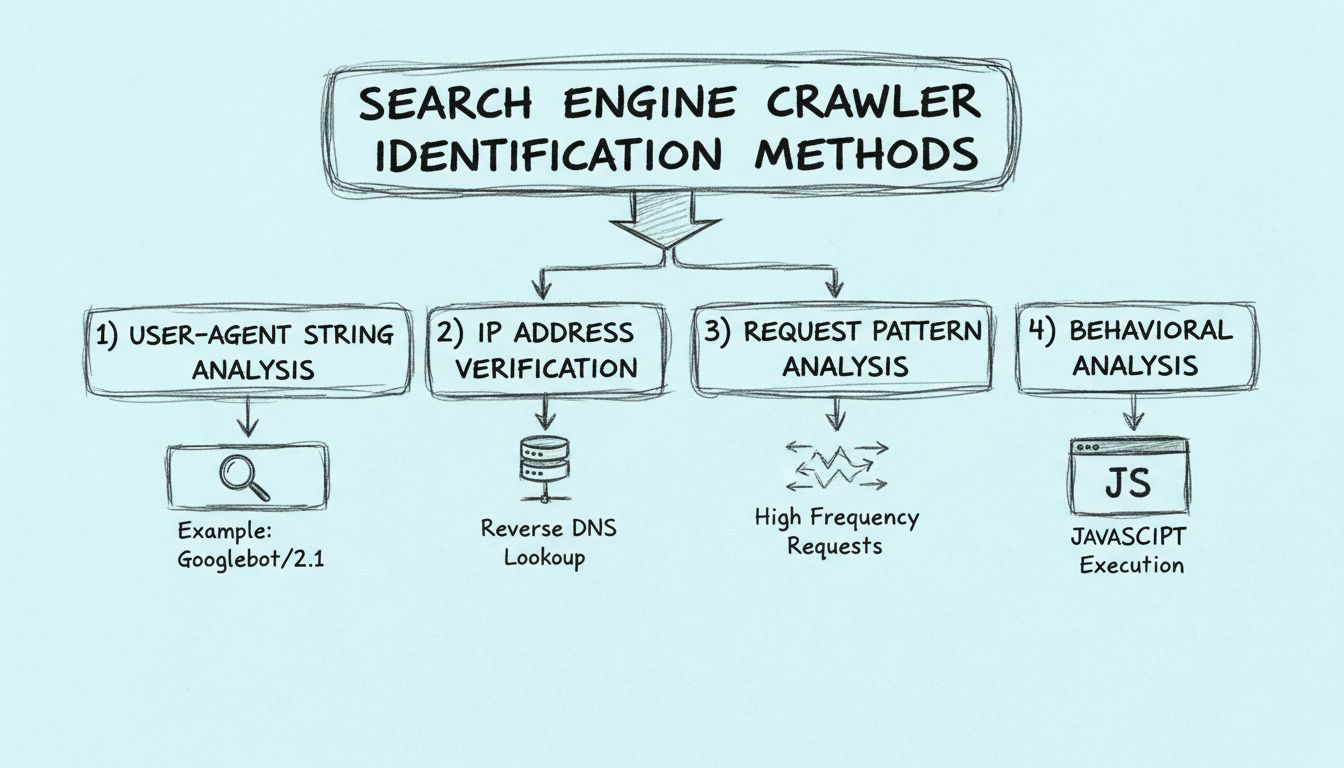
Scopri come identificare i crawler dei motori di ricerca utilizzando stringhe user-agent, indirizzi IP, pattern di richiesta e analisi comportamentale. Guida es...
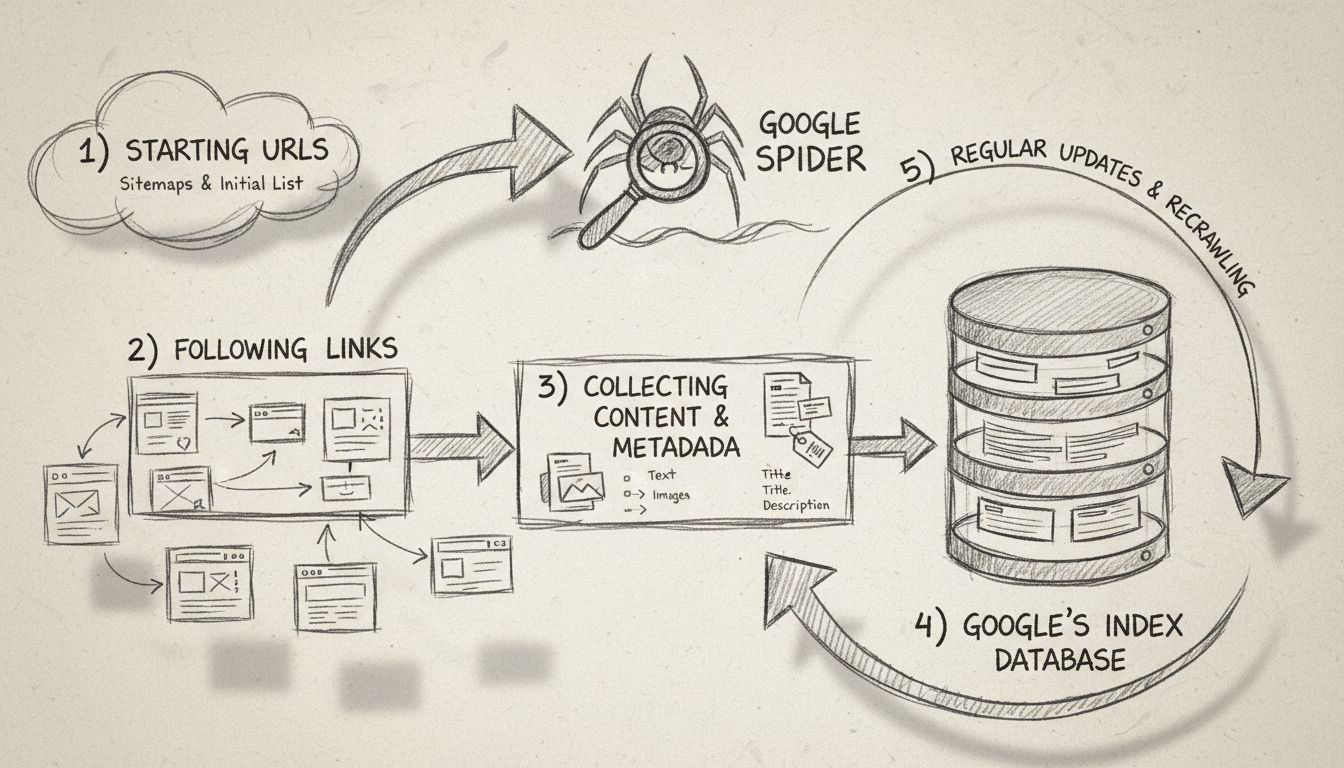
Scopri cos'è lo Spider di Google (Googlebot), come effettua il crawling e l'indicizzazione dei siti web e perché è fondamentale per la SEO. Impara come ottimizz...
Unisciti alla nostra community di clienti soddisfatti e fornisci un eccellente supporto clienti con PostAffiliatePro.
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.