
Come Funzionano i Web Crawler? Guida Tecnica Completa
Scopri come funzionano i web crawler, dagli URL seed all'indicizzazione. Comprendi il processo tecnico, i tipi di crawler, le regole del robots.txt e come i cra...
10 min di lettura
Scopri cos’è lo Spider di Google (Googlebot), come effettua il crawling e l’indicizzazione dei siti web e perché è fondamentale per la SEO. Impara come ottimizzare il tuo sito per un miglior crawling.
Lo Spider di Google, formalmente noto come Googlebot, è un programma automatico che scansiona i siti web per scoprire, indicizzare e archiviare contenuti nel database di Google. Segue i link per trovare nuove pagine o pagine aggiornate, che vengono poi elaborate e aggiunte all'indice di ricerca di Google, consentendo al motore di ricerca di fornire risultati rilevanti agli utenti.
Il Google Spider, più formalmente conosciuto come Googlebot, è un programma software automatico che esegue in modo sistematico il crawling di Internet per scoprire, analizzare e indicizzare i contenuti web. È lo strumento principale che Google utilizza per esplorare i siti, raccogliere informazioni e costruire il suo vastissimo indice di ricerca. Senza Googlebot, Google non sarebbe in grado di scoprire nuove pagine, rilevare aggiornamenti sui contenuti già esistenti o offrire risultati di ricerca pertinenti a miliardi di utenti in tutto il mondo. Lo spider opera ininterrottamente, visitando ogni giorno milioni di siti web per garantire che l’indice di Google rimanga sempre aggiornato e completo.
Googlebot è sostanzialmente un sofisticato web crawler che segue un processo algoritmico complesso per determinare quali siti visitare, con quale frequenza eseguire il crawling e quante pagine recuperare da ciascun dominio. Il crawler legge il codice HTML, il contenuto testuale e i metadati di ogni pagina visitata, quindi memorizza queste informazioni nel database centrale di Google. Questo processo di indicizzazione è fondamentale al funzionamento dei motori di ricerca e ha un impatto diretto sulla visibilità del tuo sito nei risultati di ricerca.
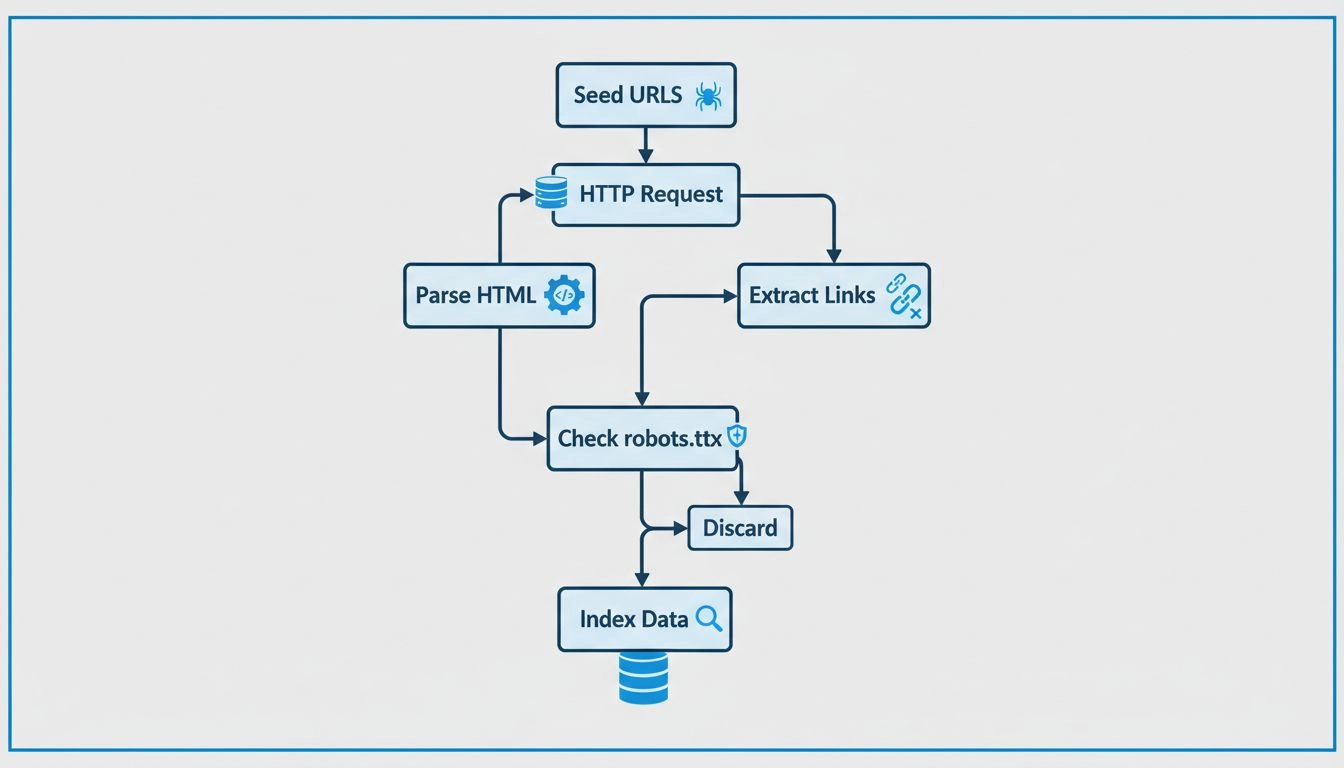
Lo Spider di Google opera attraverso un processo di crawling ben definito che inizia con una lista di pagine web già note. Questa lista iniziale viene generata dai crawl precedenti e viene costantemente arricchita con i dati delle sitemap forniti dai webmaster tramite Google Search Console. Quando Googlebot visita un sito, non si limita a leggere il contenuto: esegue un’analisi approfondita della struttura della pagina, segue i link interni ed esterni e identifica eventuali cambiamenti o nuovi contenuti aggiunti dall’ultima visita.
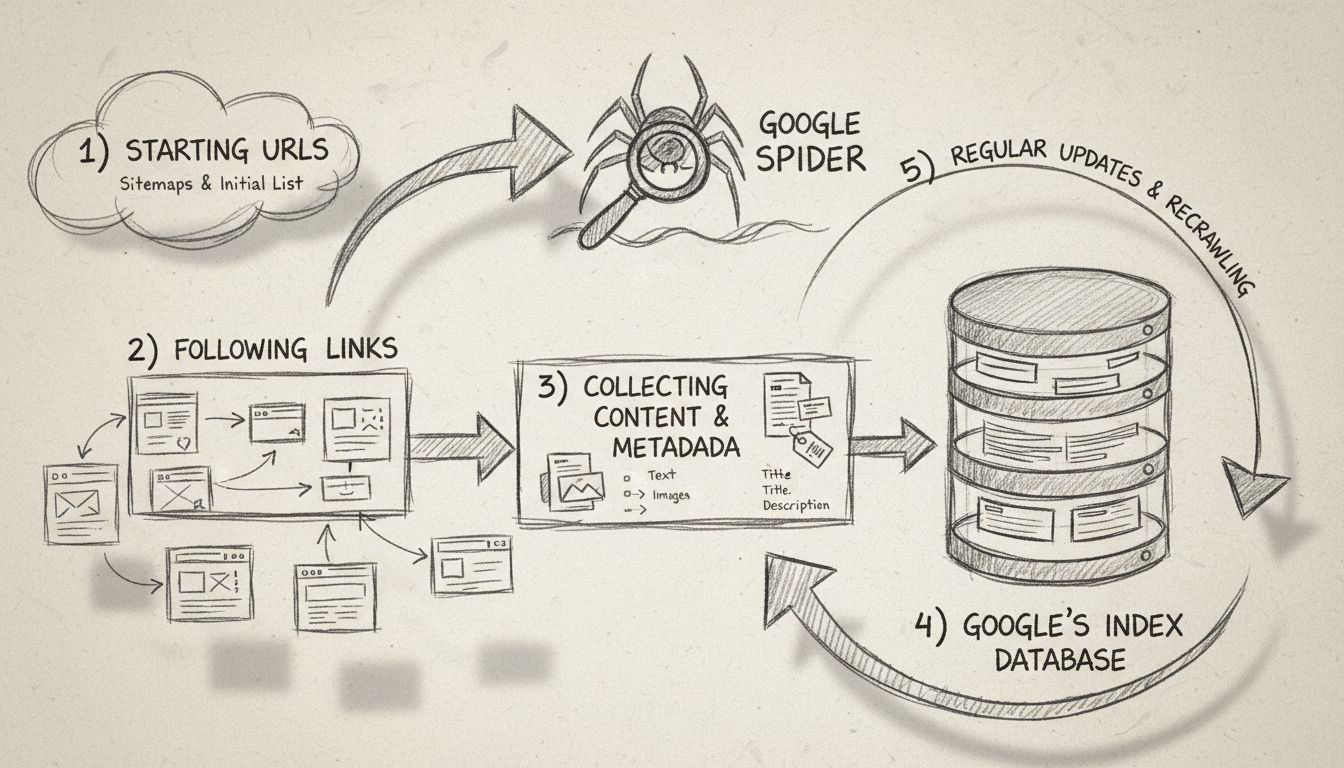
Il processo di crawling segue questi passaggi chiave: innanzitutto Googlebot parte da una lista di URL raccolta da crawl precedenti e sitemap. In secondo luogo, naviga attraverso i siti seguendo i link (sia attributi SRC che HREF) su ogni pagina per scoprire nuovi contenuti. Terzo, il crawler recupera e analizza i contenuti di ogni pagina, inclusi testo, struttura HTML, metadati e altre informazioni rilevanti. Quarto, questi dati raccolti vengono inviati ai server di Google per l’elaborazione e la memorizzazione nell’indice di ricerca. Infine, Googlebot rivisita i siti a intervalli regolari per verificare la presenza di nuovi contenuti, aggiornamenti o modifiche alle pagine esistenti.
Configura il tracciamento avanzato in pochi minuti. Nessuna carta di credito richiesta.
Google gestisce molteplici varianti specializzate di crawler, ciascuna progettata per scopi specifici e identificata da stringhe user-agent uniche. Comprendere queste diverse tipologie aiuta i proprietari di siti a ottimizzare le proprie pagine per il crawler più appropriato. Le principali varianti di Googlebot includono il crawler desktop, il crawler mobile, il crawler video, il crawler immagini e il crawler news, ognuno con una funzione distinta nell’ecosistema di indicizzazione di Google.
| Tipo di Googlebot | User-Agent String | Scopo |
|---|---|---|
| Googlebot (Desktop) | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Effettua il crawling delle versioni desktop dei siti per l’indice di ricerca generale |
| Googlebot (Mobile) | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Effettua il crawling delle versioni ottimizzate per dispositivi mobili |
| Googlebot-Video | Googlebot-Video/1.0 | Indicizza i contenuti video incorporati nelle pagine web |
| Googlebot-Image | Googlebot-Image/1.0 | Esegue il crawling e l’indicizzazione delle immagini per la ricerca Google Immagini |
| Googlebot-News | Googlebot-News | Effettua il crawling dei contenuti news per l’aggregazione di Google News |
Oltre a questi crawler principali, Google gestisce anche bot specializzati per altri scopi. AdSense Bot verifica la qualità e la conformità degli annunci, mentre il crawler Mobile Apps Android indicizza i contenuti delle applicazioni Android. Ogni bot ha un user-agent identificativo specifico che consente agli amministratori dei siti di tracciare quale crawler sta accedendo al proprio sito tramite i log del server. Questa distinzione è importante perché i diversi crawler possono avere budget e priorità di crawling differenti, influenzando la frequenza con cui visitano il tuo sito.
Lo Spider di Google è assolutamente fondamentale per l’ottimizzazione nei motori di ricerca perché determina se i contenuti del tuo sito vengono scoperti, indicizzati e posizionati nei risultati di ricerca. Se Googlebot non riesce a eseguire correttamente il crawling del tuo sito, le tue pagine non appariranno nell’indice di Google, rendendole invisibili ai potenziali visitatori che cercano i tuoi prodotti o servizi. Ecco perché la SEO tecnica—rendere il sito facilmente accessibile ai crawler—è una delle basi più importanti di ogni strategia SEO di successo.

Quando Googlebot esegue il crawling del tuo sito, compila un enorme indice di tutte le parole trovate e delle loro posizioni in ciascuna pagina, insieme a informazioni HTML come tag title, meta descrizioni e strutture di intestazione. Queste informazioni indicizzate vengono archiviate nel database di Google e utilizzate dagli algoritmi di ricerca per posizionare le pagine e valutare quanto i tuoi contenuti siano rilevanti per specifiche query di ricerca. Più efficacemente Googlebot riesce a eseguire il crawling del tuo sito, più frequentemente tornerà e più velocemente i nuovi contenuti saranno indicizzati e potenzialmente posizionati nei risultati di ricerca.
Sii il primo a conoscere le nuove funzionalità e gli aggiornamenti del prodotto.
Per assicurarti che Googlebot possa scansionare in modo efficace ed efficiente il tuo sito, è necessario applicare alcune best practice tecniche. Prima di tutto, mantieni una struttura del sito chiara e logica con una navigazione adeguata che faciliti al crawler la scoperta di tutte le pagine importanti. Il linking interno dovrebbe essere strategico e pertinente, utilizzando anchor text descrittivi che aiutino sia gli utenti sia i crawler a comprendere il contesto delle pagine collegate. Il tuo sito dovrebbe caricarsi velocemente, poiché la velocità delle pagine incide sull’efficienza del crawling e sulla quantità di contenuti che Googlebot scansionerà entro il budget di crawling assegnato.
Crea e invia una sitemap XML tramite Google Search Console, che fornisce a Googlebot un elenco completo di tutte le pagine che desideri indicizzare. Questo è particolarmente importante per siti di grandi dimensioni o con pagine difficili da raggiungere tramite il solo linking interno. Inoltre, assicurati che il file robots.txt sia configurato correttamente per consentire a Googlebot di accedere alle pagine da indicizzare, bloccando invece aree sensibili o contenuti duplicati. Tuttavia, presta attenzione a non bloccare accidentalmente pagine importanti, perché in tal caso non verranno proprio indicizzate.
Google Search Console è uno strumento essenziale per monitorare come Googlebot interagisce con il tuo sito e individuare eventuali problemi di crawling che potrebbero impedirne la corretta indicizzazione. La sezione Statistiche di scansione fornisce informazioni dettagliate su quante pagine Googlebot ha scansionato, quanto tempo ha impiegato a scansionare il tuo sito e quanti errori ha riscontrato. Puoi visualizzare il tempo medio di risposta del tuo server, che influisce direttamente sull’efficienza di crawling—server più lenti significano meno pagine scansionate nello stesso intervallo di tempo.
Il report Copertura in Google Search Console mostra quali pagine sono state indicizzate correttamente, quali presentano errori che impediscono l’indicizzazione e quali sono escluse dall’indice. Queste informazioni sono preziose per identificare problemi tecnici come link interrotti, errori del server o pagine bloccate dal robots.txt che potresti non aver intenzione di escludere. Puoi anche utilizzare lo strumento di Ispezione URL per testare come Googlebot vede una pagina specifica, incluso se riesce a renderizzare i contenuti JavaScript e ad accedere a tutte le risorse necessarie per visualizzare correttamente la pagina.
Ogni sito ha un “budget di crawling”—ossia il numero di pagine che Googlebot scansiona sul tuo sito in un determinato periodo di tempo. Per la maggior parte dei siti, il crawl budget non è un limite, ma per siti molto grandi con migliaia o milioni di pagine, ottimizzare il crawl budget diventa importante. Google assegna il crawl budget in base a due fattori: la capacità di crawling (quanto il tuo server può gestire) e la domanda di crawling (quanto Google considera importante il tuo sito). Migliorare la velocità del sito e correggere gli errori di crawling aumenta la capacità di crawling, mentre creare contenuti di qualità e aggiornati frequentemente aumenta la domanda di crawling.
Per ottimizzare il tuo crawl budget, elimina contenuti duplicati che sprecano risorse di scansione, correggi link interrotti e catene di redirect, e rimuovi pagine che non apportano valore agli utenti. Evita di bloccare pagine importanti tramite robots.txt o tag noindex e assicurati che la struttura del sito consenta a Googlebot di scoprire tutte le pagine fondamentali con pochi click dalla homepage. Aggiorna regolarmente la sitemap XML e rimuovi pagine obsolete, così Googlebot potrà concentrare la scansione su ciò che conta davvero per il tuo business.
I proprietari di siti si trovano spesso ad affrontare vari problemi che impediscono a Googlebot di scansionare efficacemente le proprie pagine. Gli errori del server (codici di stato 5xx) indicano che il server ha problemi a rispondere alle richieste, il che può impedire l’indicizzazione delle pagine. Le catene di redirect—dove una pagina ne reindirizza un’altra che a sua volta ne reindirizza un’altra ancora—sprecano crawl budget e rallentano il processo di indicizzazione. Risorse bloccate, come file CSS o JavaScript bloccati tramite robots.txt, possono impedire a Googlebot di renderizzare e comprendere correttamente le tue pagine.
Gli errori soft 404 si verificano quando una pagina restituisce un codice di stato 200 (successo) ma contiene pochi o nessun contenuto reale, confondendo Googlebot su come indicizzarla. Tag noindex applicati per errore a pagine importanti ne impediscono la presenza nei risultati di ricerca. Tempi di caricamento lenti riducono il numero di pagine che Googlebot può esaminare entro il budget assegnato. Per risolvere questi problemi, esegui periodicamente audit del sito con Google Search Console, monitora i log del server alla ricerca di errori di crawling e utilizza strumenti come Screaming Frog per individuare problemi tecnici prima che impattino la tua visibilità organica.
Nel 2025, lo Spider di Google rimane fondamentale, anche se il suo ruolo si è evoluto per adattarsi a nuove tecnologie e formati di contenuto. Googlebot ora gestisce il rendering JavaScript, quindi può scansionare e indicizzare contenuti generati dinamicamente da framework JavaScript. Processa anche i dati strutturati (Schema.org) per comprendere meglio i contenuti delle pagine e fornire rich snippet nei risultati di ricerca. L’indicizzazione mobile-first significa che Googlebot dà priorità al crawling e all’indicizzazione della versione mobile del tuo sito, rendendo l’ottimizzazione mobile essenziale per la SEO.
Lo spider svolge inoltre un ruolo cruciale nella capacità di Google di rilevare e combattere lo spam, individuare contenuti hackerati e garantire che i risultati di ricerca restino pertinenti e affidabili. Man mano che i motori di ricerca evolvono con l’intelligenza artificiale e le tecnologie di machine learning, le capacità di crawling e indicizzazione di Googlebot diventano sempre più sofisticate, permettendo a Google di comprendere meglio l’intento degli utenti e offrire risultati di ricerca sempre più precisi. Capire come funziona Googlebot e ottimizzare di conseguenza il proprio sito resta uno degli aspetti più fondamentali della strategia SEO.
Proprio come lo Spider di Google esegue il crawling e l'indicizzazione dei tuoi contenuti, PostAffiliatePro ti aiuta a monitorare e ottimizzare le tue performance di marketing affiliato. Tieni traccia di ogni click, conversione e commissione con la nostra piattaforma leader nella gestione degli affiliati.
Scopri come funzionano i web crawler, dagli URL seed all'indicizzazione. Comprendi il processo tecnico, i tipi di crawler, le regole del robots.txt e come i cra...
I crawler accumulano dati e informazioni da Internet visitando siti web e leggendo le pagine. Scopri di più su di loro.
Gli spider sono bot creati per lo spamming, che possono causare molti problemi alla tua attività. Scopri di più su di loro nell'articolo.
Unisciti alla nostra community di clienti soddisfatti e fornisci un eccellente supporto clienti con PostAffiliatePro.
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.