
SEO Spider: Perché Sono Importanti per il Tuo Sito
Gli spider sono bot creati per lo spamming, che possono causare molti problemi alla tua attività. Scopri di più su di loro nell'articolo.
4 min di lettura
SEO
DigitalMarketing
+3
Scopri perché i web crawler sono chiamati spider, come funzionano e il loro ruolo fondamentale nell’indicizzazione dei motori di ricerca. Esplora i meccanismi tecnici dietro il web crawling nel 2025.
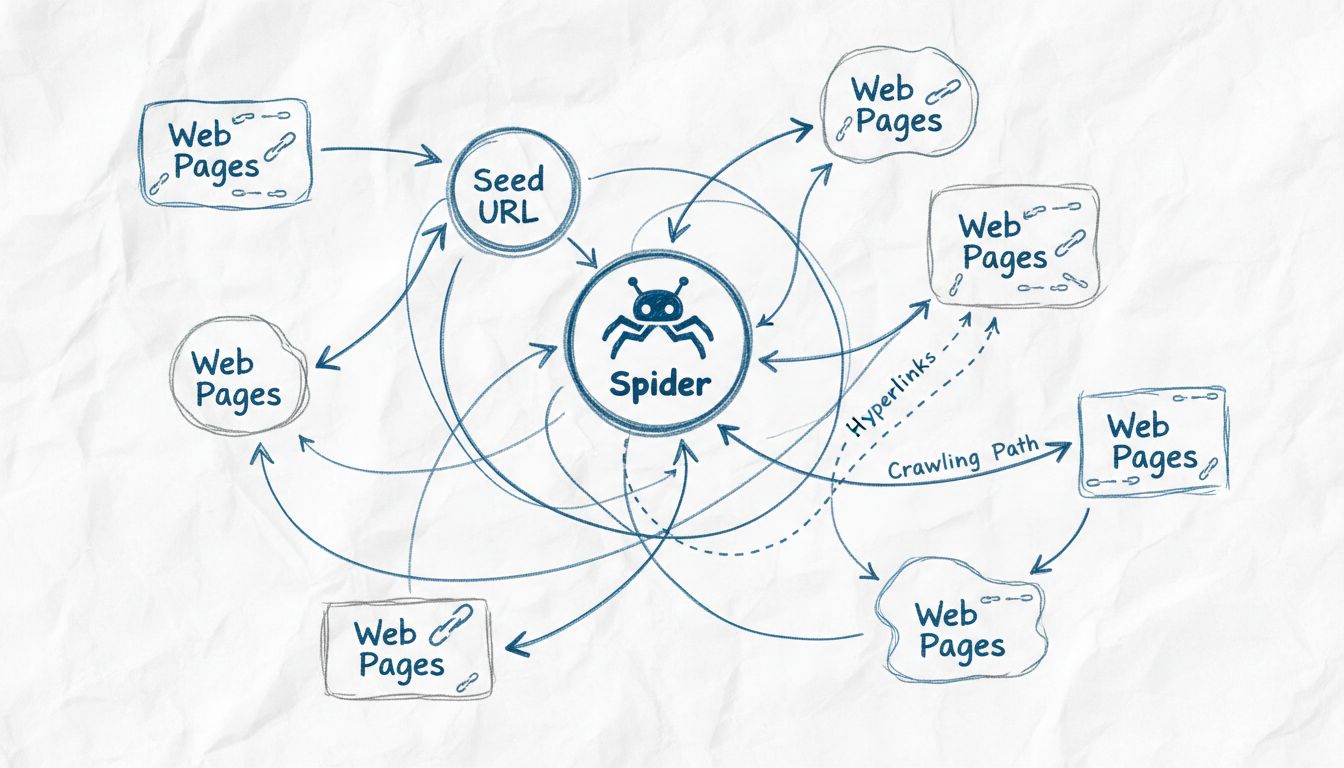
I web crawler sono chiamati spider perché esplorano sistematicamente il web seguendo i link da una pagina all’altra, proprio come un ragno si muove sulla sua ragnatela. Il termine 'spider' è una metafora adatta per questi bot automatici che attraversano la rete interconnessa dei siti web per scoprire, indicizzare e organizzare i contenuti per i motori di ricerca.
Il termine “spider” per i web crawler nasce da un’abile metafora che paragona il modo in cui questi bot automatici navigano su Internet a come i ragni reali si muovono sulla loro ragnatela. Proprio come un ragno tesse una ragnatela intricata per catturare e organizzare informazioni sul proprio ambiente, i web crawler attraversano la rete interconnessa di hyperlink del World Wide Web per scoprire, analizzare e organizzare contenuti digitali. La metafora è particolarmente efficace perché entrambe le entità operano in modo sistematico attraverso reti complesse, seguendo percorsi per raggiungere nuove destinazioni e raccogliere informazioni. Questa convenzione di denominazione è talmente radicata nella tecnologia che i termini “spider”, “crawler” e “bot” sono ormai usati in modo intercambiabile quando si parla di tecnologie di indicizzazione web. La somiglianza visiva e concettuale tra la ragnatela di un ragno e la struttura di Internet rende questa terminologia sia intuitiva che memorabile per professionisti del settore e utenti comuni.
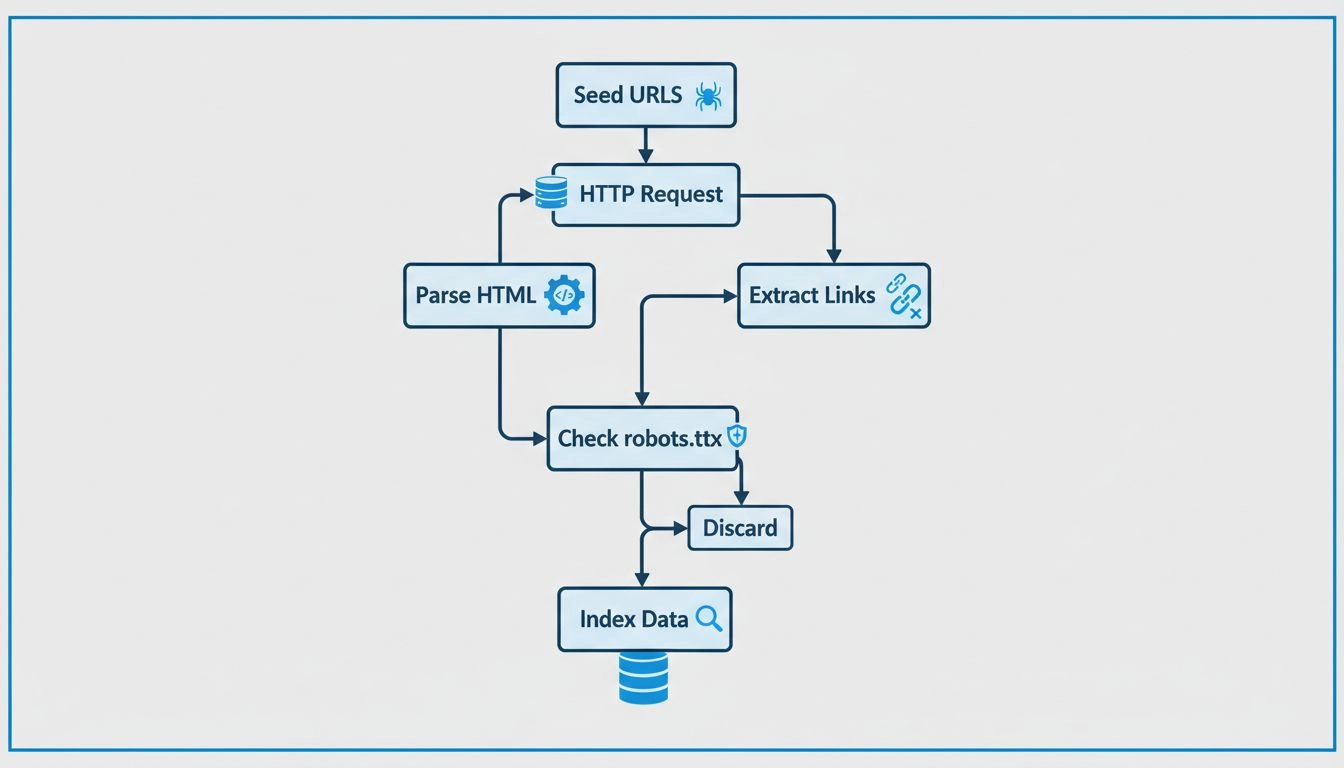
Gli spider del web operano attraverso un processo sofisticato ma sistematico che inizia da un singolo punto d’ingresso chiamato “seed URL”. Da questa posizione iniziale, lo spider analizza il codice HTML della pagina web, estraendo tutti gli hyperlink presenti su quella pagina. Lo spider segue poi questi link verso nuove pagine, ripetendo continuamente il processo per espandere la propria copertura sul web. Questo approccio metodico consente agli spider di scoprire milioni di pagine interconnesse senza la necessità di una guida manuale o dell’intervento umano. Lo spider mantiene quella che viene chiamata “crawl frontier”, ovvero una coda di URL che sono stati scoperti ma non ancora visitati. In base a specifiche politiche e algoritmi di crawling, lo spider dà priorità agli URL da visitare successivamente, considerando fattori come l’importanza della pagina, la frequenza di aggiornamento e la rilevanza rispetto agli obiettivi di indicizzazione del motore di ricerca.
Configura il tracciamento avanzato in pochi minuti. Nessuna carta di credito richiesta.
I moderni spider del web si basano su un’architettura tecnica sofisticata che consente loro di elaborare grandi quantità di dati in modo efficiente. I componenti principali di un web crawler includono il sistema di gestione della URL frontier, che organizza e dà priorità agli URL da esplorare; il meccanismo di fetch, che scarica i contenuti delle pagine ad alta velocità; il motore di parsing, che estrae link e metadati dall’HTML; e il sistema di indicizzazione, che archivia le informazioni elaborate per il recupero nelle ricerche. Gli spider devono anche implementare politiche di cortesia per evitare di sovraccaricare i server di destinazione con richieste eccessive, politiche di rivisita per stabilire la frequenza con cui le pagine devono essere riesplorate, e politiche di selezione per decidere quali link sono più preziosi da seguire. Gli spider contemporanei si sono evoluti per gestire contenuti JavaScript e AJAX, anche se danno ancora priorità all’HTML standard per una scoperta di contenuti affidabile. La natura distribuita del crawling moderno significa che gli spider su larga scala operano su più server simultaneamente, permettendo loro di esplorare siti diversi in parallelo e aumentare così notevolmente efficienza e copertura.
Sebbene i termini “spider” e “crawler” siano spesso usati come sinonimi, è importante capire che rappresentano la stessa tecnologia con denominazioni diverse. Tuttavia, i web spider si differenziano notevolmente dai web scraper, spesso confusi con i crawler. La differenza principale risiede nello scopo e nell’ambito: i web crawler si concentrano sulla raccolta generale di informazioni sui siti web e sulla loro struttura, seguendo i link su larga scala per costruire indici completi. Gli spider, quando usati specificamente dai motori di ricerca, puntano a indicizzare il contenuto testuale per renderlo ricercabile e facilmente individuabile. Gli scraper, invece, sono strumenti di precisione progettati per estrarre dati specifici da siti web, come prezzi di prodotti, informazioni di contatto o recensioni. Gli scraper in genere prendono di mira siti o tipi di dati specifici invece di esplorare ampiamente il web. Inoltre, crawler e spider rispettano generalmente i file robots.txt e i termini di servizio dei siti, mentre gli scraper possono operare senza tali vincoli. Comprendere queste distinzioni è fondamentale per i proprietari e gli sviluppatori di siti web che devono gestire l’accesso e l’indicizzazione dei propri contenuti da parte di sistemi automatizzati.
Sii il primo a conoscere le nuove funzionalità e gli aggiornamenti del prodotto.
I web spider sono assolutamente fondamentali per il funzionamento dei motori di ricerca e il valore che offrono agli utenti di tutto il mondo. Senza spider che esplorano e indicizzano continuamente i contenuti, i motori di ricerca non avrebbero modo di sapere quali siti esistono, quali contenuti ospitano o quanto questi siano rilevanti per le query degli utenti. Quando uno spider esplora una pagina web, valuta numerosi fattori tra cui la struttura della pagina, la rilevanza dei contenuti, l’uso delle parole chiave e i segnali di esperienza utente. Queste informazioni vengono poi archiviate in enormi indici utilizzati dai motori di ricerca per abbinare le query degli utenti ai risultati più pertinenti. La qualità e la frequenza del crawling degli spider influenzano direttamente la rapidità con cui i nuovi contenuti compaiono nei risultati di ricerca e la precisione con cui i motori possono classificare le pagine. Motori di ricerca come Google, Bing, Baidu e Yahoo mantengono ciascuno i propri spider proprietari—Googlebot, Bingbot, Baiduspider e Slurp rispettivamente—ognuno con algoritmi e strategie di crawling ottimizzati per le proprie esigenze e il proprio pubblico.
| Spider Bot | Motore di ricerca | Funzione principale | Strategia di crawling | Caratteristiche chiave |
|---|---|---|---|---|
| Googlebot | Indicizzare pagine web per la ricerca Google | Crawling distribuito con varianti mobile e desktop | Gestisce JavaScript, priorità al mobile-first indexing, rispetta il crawl budget | |
| Bingbot | Microsoft Bing | Indicizzare pagine web per la ricerca Bing | Crawling parallelo su più server | Uso efficiente della banda, rispetta robots.txt, supporta diversi tipi di contenuto |
| Baiduspider | Baidu | Indicizzare pagine web per la ricerca Baidu | Ottimizzato per contenuti in lingua cinese | Specializzato per il web asiatico, gestisce cinese semplificato e tradizionale |
| DuckDuckBot | DuckDuckGo | Indicizzare pagine web per ricerca orientata alla privacy | Crawling rispettoso con attenzione alla privacy | Raccolta dati minima, rispetta le preferenze di privacy degli utenti |
| YandexBot | Yandex | Indicizzare pagine web per la ricerca Yandex | Crawling distribuito con ottimizzazione regionale | Ottimizzato per contenuti russi ed est-europei |
I proprietari dei siti hanno a disposizione diversi strumenti e strategie per ottimizzare il modo in cui gli spider esplorano e indicizzano i loro contenuti. Creare un file sitemap.xml completo fornisce agli spider una mappa chiara di tutte le pagine da indicizzare, migliorando notevolmente l’efficienza del crawling e assicurando che nessuna pagina importante venga trascurata. L’ottimizzazione dei meta tag, inclusi title e meta description, aiuta gli spider a comprendere i contenuti delle pagine e migliora l’aspetto nei risultati di ricerca. Implementare un file robots.txt ben strutturato consente ai proprietari di guidare gli spider verso i contenuti importanti e di escludere quelli che non devono essere indicizzati, come pannelli di amministrazione o contenuti duplicati. Aggiornare e aggiungere regolarmente nuovi contenuti incentiva gli spider a rivisitare il sito più spesso, mantenendo gli indici aggiornati e migliorando la visibilità nei motori di ricerca. È inoltre importante assicurarsi che l’architettura del sito sia pulita e logica, con una navigazione gerarchica chiara che faciliti agli spider la scoperta di tutte le pagine. Migliorare la velocità di caricamento delle pagine è cruciale, poiché gli spider hanno un crawl budget limitato—cioè una quantità di risorse che i motori di ricerca destinano all’esplorazione di un sito—e pagine più veloci consentono agli spider di esplorare più contenuti all’interno di quel budget.
Nonostante la loro sofisticazione, gli spider del web affrontano numerose sfide tecniche che possono limitarne l’efficacia. I contenuti dinamici generati da JavaScript rappresentano un ostacolo significativo, poiché non tutti gli spider riescono a eseguire codice JavaScript per visualizzare le pagine come fanno gli utenti. Le limitazioni di frequenza imposte dai siti web restringono il numero di richieste che gli spider possono effettuare in un certo intervallo di tempo, impedendo talvolta l’indicizzazione completa di siti molto grandi. CAPTCHA e altre misure anti-bot possono bloccare l’accesso agli spider, sebbene quelli dei motori di ricerca legittimi siano di solito inseriti in whitelist. I contenuti duplicati su più URL confondono gli spider su quale versione indicizzare e classificare, con possibile perdita di visibilità nei motori. I crawler trap—loop infiniti intenzionali o accidentali nella struttura del sito—possono far sprecare risorse agli spider e consumare il crawl budget senza produrre indicizzazione utile. Inoltre, la crescita esponenziale dei contenuti online rende impossibile per gli spider esplorare e indicizzare tutto, richiedendo algoritmi sofisticati per stabilire quali contenuti siano prioritari. Le pagine protette da password e i contenuti autenticati rimangono in gran parte inaccessibili agli spider pubblici, limitando l’indicizzazione di contenuti privati o riservati ai membri.
La tecnologia degli spider del web continua a evolversi rapidamente man mano che Internet cresce e si fa più complesso. Gli spider moderni sono sempre più capaci di gestire tecnologie web avanzate come single-page application, progressive web app e rendering dinamico dei contenuti. L’intelligenza artificiale e il machine learning vengono integrati negli algoritmi degli spider per comprendere meglio il contesto dei contenuti, l’intento dell’utente e la qualità delle pagine. L’ascesa dell’intelligenza artificiale generativa ha creato nuove esigenze di crawling, poiché i sistemi AI richiedono informazioni costantemente aggiornate, pertinenti e accurate per funzionare efficacemente. I crawler aziendali sono diventati sempre più sofisticati, permettendo alle aziende di esplorare i propri siti per funzioni di ricerca interna, gestione dei contenuti e monitoraggio delle performance. L’attenzione all’efficienza del crawling è aumentata con la crescita della complessità dei siti, portando gli spider a implementare algoritmi di prioritizzazione più intelligenti per massimizzare il valore di ogni richiesta. Anche le considerazioni sulla privacy stanno influenzando lo sviluppo degli spider, con un’enfasi crescente sul rispetto della riservatezza degli utenti pur consentendo una scoperta e indicizzazione dei contenuti efficace. Guardando al futuro, gli spider del web diventeranno probabilmente ancora più intelligenti ed efficienti, sfruttando tecnologie avanzate per navigare un panorama digitale sempre più complesso, nel rispetto delle policy dei siti e della privacy degli utenti.
Così come gli spider del web esplorano e indicizzano sistematicamente l’intero web, PostAffiliatePro traccia e ottimizza ogni relazione di affiliazione nella tua rete. La nostra tecnologia di tracciamento avanzata assicura che nessuna commissione venga persa e nessuna opportunità venga trascurata.
Gli spider sono bot creati per lo spamming, che possono causare molti problemi alla tua attività. Scopri di più su di loro nell'articolo.
I crawler accumulano dati e informazioni da Internet visitando siti web e leggendo le pagine. Scopri di più su di loro.
Scopri come funzionano i web crawler, dagli URL seed all'indicizzazione. Comprendi il processo tecnico, i tipi di crawler, le regole del robots.txt e come i cra...
Unisciti alla nostra community di clienti soddisfatti e fornisci un eccellente supporto clienti con PostAffiliatePro.
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.