Perché i Web Spider sono chiamati Spider Informatici? Comprendere i Web Crawler
Scopri perché i web spider sono chiamati spider informatici e come esplorano il web. Scopri come funzionano i crawler dei motori di ricerca e la loro importanza per la SEO e il marketing di affiliazione.
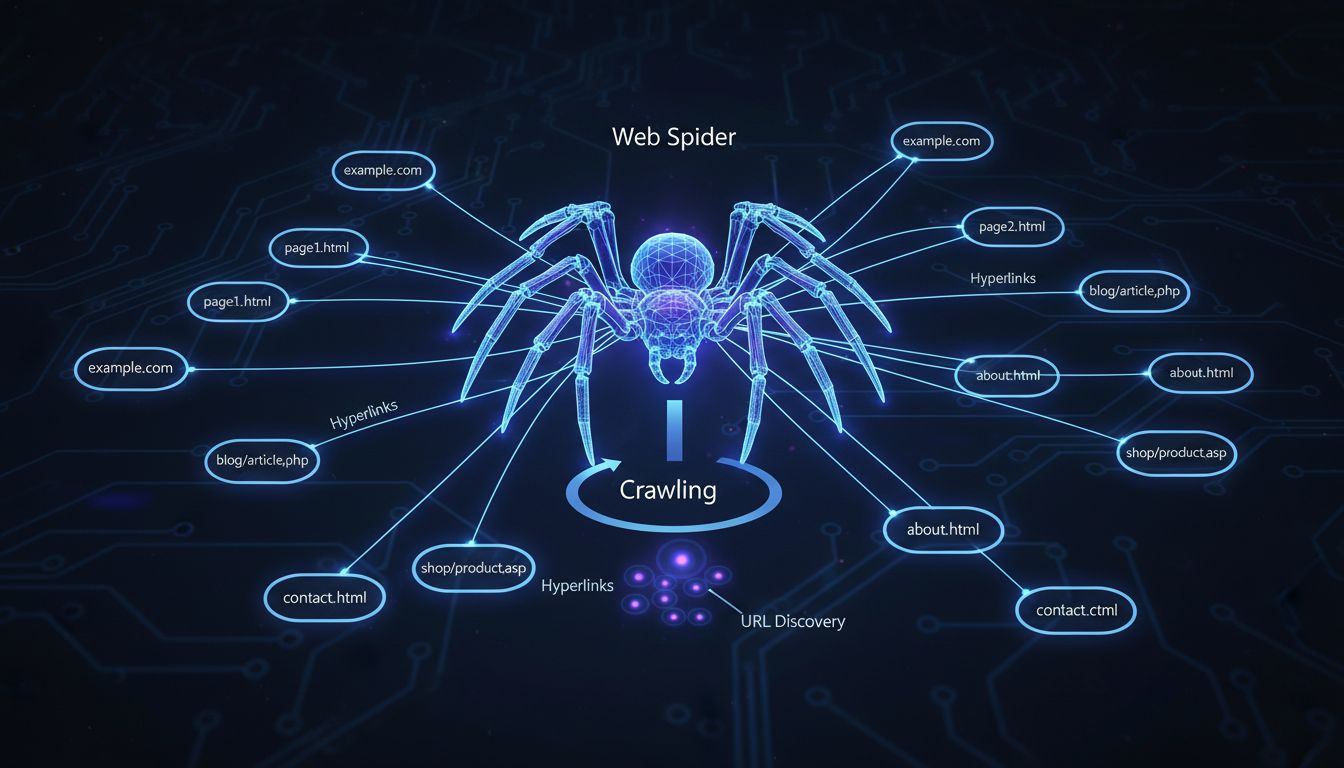
Perché sono chiamati spider informatici? Sono chiamati spider informatici perché "strisciano" sul web.
I web spider sono chiamati spider informatici perché "strisciano" attraverso Internet seguendo i collegamenti ipertestuali da una pagina all'altra, proprio come un ragno si muove sulla sua ragnatela. Questi programmi automatici esplorano sistematicamente i siti web per scoprire e indicizzare i contenuti per i motori di ricerca.
Comprendere la metafora dello Spider
Il termine “spider informatico” nasce da una brillante analogia che descrive perfettamente il funzionamento di questi programmi automatici su Internet. Proprio come un vero ragno si muove sulla sua ragnatela seguendo fili e connessioni, uno spider web naviga su Internet seguendo i collegamenti ipertestuali da una pagina web all’altra. Questa metafora è diventata così intuitiva che ormai rappresenta la terminologia standard utilizzata da sviluppatori web, professionisti SEO e digital marketer in tutto il mondo. Il nome cattura l’essenza del comportamento del crawler in modo immediatamente comprensibile sia al pubblico tecnico che a quello non tecnico. Quando comprendi questo concetto fondamentale, inizi ad apprezzare quanto elegantemente l’infrastruttura di Internet rispecchi i sistemi naturali presenti in natura.
Come i Web Spider esplorano Internet
I web spider operano attraverso un processo sistematico e metodico che inizia con una lista iniziale di URL conosciuti. Il crawler comincia visitando queste prime pagine web ed esaminando attentamente i loro contenuti e la loro struttura. Durante l’analisi di ogni pagina, lo spider identifica tutti i collegamenti ipertestuali presenti e li aggiunge a una coda di URL da visitare successivamente. Questo processo si ripete continuamente, permettendo allo spider di addentrarsi sempre più a fondo nel web ad ogni iterazione. Lo spider crea essenzialmente una mappa di Internet seguendo queste connessioni, proprio come un esploratore che traccia nuovi territori seguendo sentieri e percorsi. Questo approccio sistematico assicura che i motori di ricerca possano scoprire e catalogare milioni di nuove pagine ogni singolo giorno.
Componente del Crawler
Funzione
Scopo
Coda URL
Memorizza l’elenco delle pagine da visitare
Organizza la sequenza di crawling
Parser
Legge il contenuto delle pagine e l’HTML
Estrae link e metadati
Indicizzatore
Memorizza le informazioni delle pagine
Crea un database ricercabile
Scheduler
Determina la frequenza di crawling
Gestisce l’allocazione delle risorse
User-Agent
Identifica il crawler
Comunica con i server
Il processo tecnico dietro il Web Crawling
Prima che uno spider web inizi la sua attività di crawling, gli sviluppatori devono stabilire istruzioni chiare e predefinite che guidano il comportamento dello spider. Queste istruzioni determinano quali pagine esplorare, con quale frequenza rivisitarle e quali informazioni estrarre da ciascuna pagina. Il crawler poi esegue automaticamente queste istruzioni, seguendo l’algoritmo esattamente come programmato. Quando lo spider visita un sito web, controlla innanzitutto il file robots.txt, un file di testo che specifica le regole per l’accesso dei crawler. Questo protocollo, noto come robot exclusion protocol, consente ai proprietari dei siti di comunicare le proprie preferenze su quali aree del sito dovrebbero essere esplorate e quali invece evitate. Le informazioni raccolte dal crawler dipendono interamente dalle istruzioni specifiche fornitegli, rendendo la fase di configurazione cruciale per ottenere i risultati desiderati.
Tipi diversi di Web Spider
I web spider si presentano in varie forme, ognuno progettato per scopi e applicazioni specifici. Gli spider dei motori di ricerca come Googlebot sono il tipo più conosciuto, utilizzati dai principali motori di ricerca per scoprire e indicizzare pagine web per i risultati di ricerca. I crawler focalizzati, invece, limitano il loro raggio d’azione a specifici argomenti o aree di Internet, creando indici dettagliati di contenuti di nicchia. Gli spider di analisi web aiutano i webmaster a monitorare i propri siti tracciando metriche come visite, link interrotti e prestazioni delle pagine. Gli spider per il confronto prezzi raccolgono automaticamente informazioni sui prezzi da più venditori, consentendo ai siti di confronto di offrire agli utenti dati di mercato aggiornati. Gli spider di validazione email verificano gli indirizzi email e controllano eventuali problemi di recapito. Ogni tipo di spider ha uno scopo specifico nell’ecosistema digitale, e comprendere queste differenze aiuta i proprietari di siti web a ottimizzare i propri siti per i crawler appropriati.
Perché i motori di ricerca dipendono dai Web Spider
I motori di ricerca non possono funzionare senza i web spider, perché questi programmi automatici sono responsabili della scoperta di nuovi contenuti e dell’aggiornamento degli indici di ricerca. Quando effettui una ricerca, il motore di ricerca non consulta il web in tempo reale. Invece, effettua la ricerca su un indice creato dagli spider che in precedenza hanno visitato e catalogato miliardi di pagine web. Senza gli spider, i motori di ricerca non avrebbero modo di sapere quali contenuti esistono su Internet né di organizzarli per il recupero. La capacità degli spider di seguire i collegamenti ipertestuali significa che le nuove pagine possono essere scoperte automaticamente senza richiedere una segnalazione manuale. Questo processo di scoperta automatica è ciò che rende Internet ricercabile e accessibile a miliardi di utenti in tutto il mondo. L’efficienza e la velocità dei web spider influiscono direttamente sulla rapidità con cui i nuovi contenuti appaiono nei risultati di ricerca.
L’importanza dei Web Spider per SEO e Digital Marketing
Per i proprietari di siti web e i digital marketer, comprendere i web spider è fondamentale perché questi crawler determinano se i tuoi contenuti appariranno nei risultati di ricerca. Se uno spider di un motore di ricerca non può esplorare il tuo sito, le tue pagine non verranno indicizzate e non compariranno nei risultati, indipendentemente dalla qualità dei tuoi contenuti. Ecco perché i professionisti SEO pongono molta attenzione nel rendere i siti “crawler-friendly”, assicurando una struttura adeguata, tempi di caricamento rapidi e una navigazione chiara. I marketer di affiliazione, in particolare, traggono beneficio dalla comprensione del comportamento degli spider perché influisce direttamente su come le loro pagine di affiliazione vengono scoperte e classificate. PostAffiliatePro riconosce che il successo dei programmi di affiliazione dipende dalla visibilità e la nostra piattaforma ti aiuta a ottimizzare la rete di affiliati affinché i crawler dei motori di ricerca possano facilmente scoprire e indicizzare i tuoi contenuti di affiliazione. Rendendo le tue pagine di affiliazione accessibili ai crawler, aumenti la probabilità che potenziali affiliati e clienti trovino il tuo programma tramite la ricerca organica.
Gestire e controllare l’attività dei Web Spider
I proprietari dei siti web dispongono di diversi strumenti per gestire il modo in cui i web spider interagiscono con i loro siti. Il file robots.txt è il meccanismo principale per comunicare le preferenze ai crawler, consentendo di specificare quali pagine devono essere esplorate e quali evitate. Il meta tag noindex offre un controllo aggiuntivo impedendo l’indicizzazione di pagine specifiche anche se vengono esplorate. Per le pagine che dovrebbero essere esplorate ma non indicizzate, l’attributo nofollow può essere utilizzato nei link per impedire agli spider di seguire quelle connessioni particolari. I proprietari dei siti possono anche utilizzare Google Search Console e altri strumenti per webmaster per monitorare l’attività dei crawler e identificare eventuali problemi che potrebbero ostacolare una corretta indicizzazione. Tuttavia, è importante notare che, sebbene questi strumenti aiutino a gestire i legittimi spider dei motori di ricerca, i bot malevoli e gli scraper potrebbero ignorare queste direttive. Per questo motivo molti siti implementano ulteriori sistemi di sicurezza e gestione dei bot per proteggersi da attività di crawling dannose, consentendo comunque agli spider utili di accedere ai propri contenuti.
La differenza tra Spider e Scraper
Sebbene i web spider e i web scraper raccolgano entrambi automaticamente dati dai siti web, essi servono a scopi molto diversi e operano secondo linee guida etiche differenti. I web spider, in particolare quelli utilizzati dai motori di ricerca, seguono il protocollo robots.txt e rispettano le preferenze dei proprietari dei siti su quali contenuti esplorare. Gli scraper, invece, spesso ignorano queste direttive e copiano intere pagine di contenuti per ripubblicarle altrove, il che può costituire una violazione del copyright e del diritto d’autore. Gli spider di solito raccolgono e organizzano i metadati delle pagine, mentre gli scraper copiano tutti i contenuti visibili. Gli spider dei motori di ricerca sono generalmente considerati benefici perché aiutano i siti a guadagnare visibilità, mentre gli scraper sono tipicamente visti come malevoli perché rubano contenuti e possono danneggiare le prestazioni del sito. Comprendere questa differenza è importante per i proprietari di siti web che devono distinguere tra traffico di crawler legittimo e attività di bot dannose. PostAffiliatePro aiuta i manager di affiliazione a monitorare e gestire il traffico verso le loro pagine di affiliazione, garantendo che gli spider legittimi possano accedere ai tuoi contenuti proteggendo al contempo da attività di scraping malevole.
Massimizza la visibilità della tua rete di affiliazione
Proprio come i web spider scoprono e indicizzano i tuoi contenuti, PostAffiliatePro ti aiuta a scoprire e gestire l'intera rete di affiliati. Traccia ogni interazione dei crawler e ottimizza le prestazioni del tuo programma di affiliazione con la nostra piattaforma leader di settore.
Perché i web crawler sono chiamati spider? Comprendere la tecnologia di indicizzazione web
Scopri perché i web crawler sono chiamati spider, come funzionano e il loro ruolo fondamentale nell'indicizzazione dei motori di ricerca. Esplora i meccanismi t...
Cos'è un virus informatico Spider? Definizione, minacce e guida alla protezione
Scopri cosa sono i virus informatici spider, come si diffondono nelle reti e quali sono le strategie efficaci di protezione. Guida completa per comprendere le m...
8 min di lettura
Sarai in buone mani!
Unisciti alla nostra community di clienti soddisfatti e fornisci un eccellente supporto clienti con PostAffiliatePro.