
Perché i link sono importanti su un sito web? Guida SEO completa
Scopri perché i link sono fondamentali per il successo di un sito web. Impara come i link interni ed esterni migliorano la SEO, l’esperienza utente e la scansio...
12 min di lettura
Scopri come funzionano i link dei siti web, comprendi la struttura degli URL, la risoluzione DNS e il processo tecnico alla base della navigazione web. Guida esperta per il 2025.
I link dei siti web funzionano utilizzando gli URL (Uniform Resource Locator) che indirizzano i browser a pagine web specifiche. Quando clicchi su un link o digiti un URL, il tuo browser usa il DNS per tradurre il nome di dominio in un indirizzo IP, quindi si connette al server e recupera il contenuto richiesto della pagina.
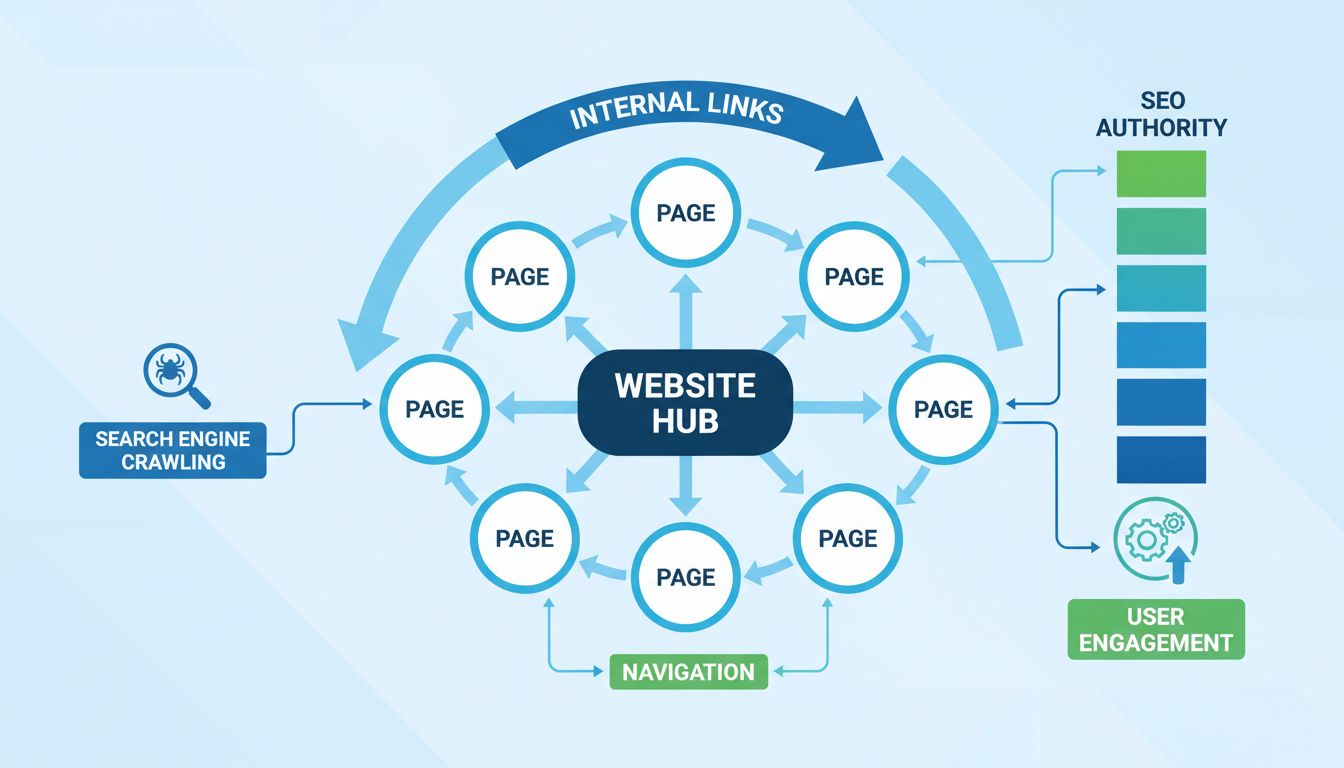
I link dei siti web sono i mattoni fondamentali della navigazione online, permettendo agli utenti di spostarsi facilmente tra pagine e risorse su Internet. Un link di un sito web è essenzialmente un URL (Uniform Resource Locator) che indirizza un utente a una pagina precisa di un sito. Affinché un link funzioni correttamente, l’URL deve essere digitato in un browser esattamente come appare, oppure raggiunto tramite un collegamento ipertestuale. Il funzionamento dei link dei siti web coinvolge più livelli tecnologici che operano in perfetta armonia, dalla barra degli indirizzi del browser fino ai server remoti che ospitano i contenuti desiderati.
Comprendere come funzionano i link dei siti web è essenziale per chiunque si occupi di sviluppo web, marketing digitale o affiliate marketing. Quando clicchi su un collegamento ipertestuale o inserisci manualmente un URL nella barra degli indirizzi, dietro le quinte si svolge una serie di eventi complessi. Il browser deve individuare il protocollo utilizzato, localizzare il server corretto tramite il Domain Name System (DNS), richiedere la risorsa specifica e infine visualizzare il contenuto. Questo processo avviene solitamente in pochi secondi, ma coinvolge diversi computer e sistemi che comunicano tra loro attraverso la rete.
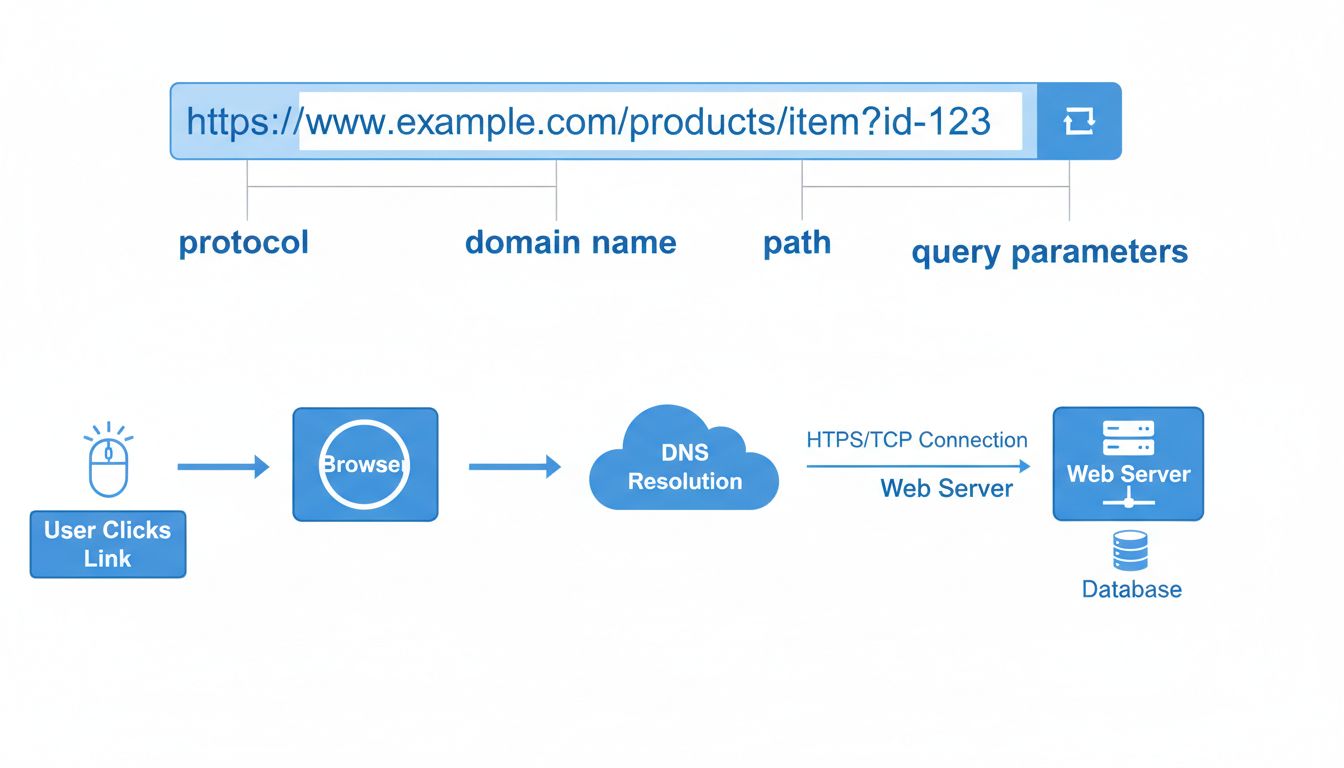
Un URL è composto da diversi elementi distinti, ognuno con un ruolo specifico nell’indirizzare il browser alla risorsa corretta. Comprendere questi elementi è fondamentale per capire come funzionano i link dei siti web e perché la precisione è importante durante l’inserimento degli URL. La struttura base di un URL segue questo schema: protocollo://sottodominio.dominio.estensione/percorso?parametri#frammento. Ognuno di questi elementi svolge un ruolo cruciale nella navigazione e l’assenza o l’errata compilazione di uno di essi può causare link non funzionanti o connessioni fallite.
| Componente URL | Esempio | Scopo |
|---|---|---|
| Protocollo | https:// | Specifica il metodo di comunicazione (HTTP o HTTPS) |
| Sottodominio | www | Organizza le diverse sezioni di un sito |
| Nome Dominio | example | Identificativo univoco del sito web |
| Estensione (TLD) | .com | Dominio di primo livello che indica il tipo/paese del sito |
| Percorso | /products/item | Specifica la pagina esatta o la posizione della risorsa |
| Parametri | ?id=123&color=blue | Invia dati aggiuntivi al server |
| Frammento | #section-2 | Punta a una sezione specifica all’interno di una pagina |
Il protocollo è il primo componente fondamentale di ogni URL. HTTPS (Hypertext Transfer Protocol Secure) è diventato lo standard per i siti moderni, sostituendo il vecchio protocollo HTTP. HTTPS cripta i dati trasmessi tra il browser e il server, proteggendo informazioni sensibili come password e numeri di carte di credito da possibili intercettazioni. Quando vedi l’icona del lucchetto nella barra degli indirizzi, significa che la connessione è sicura e criptata. Questo livello di sicurezza è essenziale per siti di e-commerce, piattaforme bancarie e qualsiasi sito che gestisca dati personali o finanziari.
Il nome di dominio è la parte più riconoscibile di un URL e rappresenta l’identificativo unico del sito. È composto da un dominio di secondo livello (il nome scelto, es. “example”) e da un dominio di primo livello (TLD) come .com, .org o .net. Il sottodominio, tipicamente “www”, precede il nome a scopo organizzativo. Alcuni siti utilizzano sottodomini personalizzati come “blog.example.com” o “support.example.com” per separare aree funzionali diverse. Il componente percorso indica invece la posizione esatta di una risorsa sul server, utilizzando la barra obliqua per distinguere le cartelle, similmente all’organizzazione dei file sul tuo computer.
Configura il tracciamento avanzato in pochi minuti. Nessuna carta di credito richiesta.
Quando clicchi su un collegamento o digiti un URL nella barra degli indirizzi del browser, si avvia un processo sofisticato che coinvolge più sistemi. Comprendere questo processo rivela il motivo per cui i link funzionano in un certo modo e perché possono verificarsi determinati errori. L’intero percorso, dal clic al caricamento della pagina, avviene solitamente in pochi secondi, ma comprende diverse fasi distinte che devono essere eseguite perfettamente.
Fase 1: Azione dell’Utente e Analisi dell’URL – Tutto comincia quando clicchi su un link o inserisci manualmente un URL: il browser analizza subito l’URL, suddividendolo nei suoi componenti: protocollo, nome dominio, percorso, parametri e frammenti. Questa analisi è fondamentale perché il browser deve comprendere ogni parte per sapere come procedere. Se l’URL contiene errori di sintassi o caratteri non validi, il browser può rifiutarlo o tentare di correggerlo automaticamente.
Fase 2: Identificazione del Protocollo – Il browser esamina il protocollo specificato nell’URL (di solito HTTPS o HTTP) per determinare come stabilire la connessione col server. Il protocollo definisce le regole di comunicazione tra browser e server. Le connessioni HTTPS richiedono handshake di sicurezza per stabilire un tunnel criptato, mentre HTTP è più semplice ma meno sicuro. I browser moderni avvertono sempre più spesso gli utenti quando visitano siti HTTP, favorendo l’adozione di HTTPS.
Fase 3: Risoluzione DNS – È forse la fase più cruciale. Il browser deve tradurre il nome di dominio leggibile (es. www.example.com ) in un indirizzo IP numerico comprensibile dai computer. Questa traduzione avviene tramite il Domain Name System (DNS), una rete distribuita di server che gestisce un enorme database di nomi di dominio e relativi indirizzi IP. Il browser invia una richiesta DNS a un resolver, che cerca nel sistema DNS il nameserver autorevole del dominio. Una volta trovato, il resolver recupera l’indirizzo IP e lo restituisce al browser. Questo processo dura pochi millisecondi ma è essenziale per stabilire la connessione.
Fase 4: Connessione al Server – Con l’indirizzo IP ottenuto, il browser stabilisce la connessione con il server che ospita il sito. Per HTTPS, ciò comporta un handshake TLS (Transport Layer Security) durante il quale browser e server si scambiano chiavi crittografiche per creare una connessione criptata e sicura. Questo handshake verifica l’identità del server tramite certificati digitali e garantisce che tutte le comunicazioni successive siano criptate. Per HTTP, il browser stabilisce semplicemente una connessione TCP sulla porta 80 (o 443 per HTTPS).
Fase 5: Richiesta HTTP – Una volta stabilita la connessione, il browser invia una richiesta HTTP al server, specificando quale risorsa desidera ottenere. Questa richiesta include il percorso dell’URL, eventuali parametri o query string e intestazioni aggiuntive con informazioni sul browser, lingua preferita e altri metadati. Il server riceve e processa la richiesta, determinando quale file o risorsa restituire.
Fase 6: Risposta del Server – Il server elabora la richiesta e invia una risposta HTTP contenente la risorsa richiesta. Questa risposta include un codice di stato (ad esempio 200 per successo, 404 per non trovato, 500 per errore), intestazioni con metadati e il contenuto vero e proprio (HTML, CSS, JavaScript, immagini, ecc.). Il server può anche impostare cookie o altre informazioni di tracciamento.
Fase 7: Rendering del Contenuto – Il browser riceve la risposta e inizia a renderizzare il contenuto. Analizza l’HTML per la struttura della pagina, applica i CSS per la formattazione e esegue JavaScript per l’interattività. Se la pagina fa riferimento a risorse esterne (immagini, fogli di stile, script), il browser effettua ulteriori richieste per recuperarle. Il processo continua fino al caricamento completo della pagina e della sua interattività.
Il Domain Name System (DNS) è l’infrastruttura invisibile che permette ai link dei siti web di funzionare traducendo i nomi di dominio in indirizzi IP. Senza il DNS, dovresti memorizzare indirizzi IP numerici complessi invece di semplici nomi come “example.com”. Il DNS opera come un sistema gerarchico e distribuito, con vari livelli di server che collaborano per risolvere i nomi di dominio. Quando inserisci un URL nel browser, il processo di risoluzione DNS parte immediatamente e il browser non può procedere finché non riceve l’indirizzo IP del dominio.
La risoluzione DNS coinvolge diversi tipi di server. Il browser contatta prima un resolver ricorsivo, fornito solitamente dal tuo provider Internet (ISP) o da servizi DNS pubblici come Google DNS o Cloudflare DNS. Questo resolver si occupa di trovare la risposta alla richiesta consultando altri server. Se non ha la risposta in cache, contatta un root nameserver, che lo indirizza al nameserver del TLD appropriato. Quest’ultimo indirizza poi il resolver al nameserver autorevole del dominio, che fornisce infine l’indirizzo IP. Questo processo, detto ricorsione DNS, avviene in modo trasparente e dura pochi millisecondi.
La cache DNS è fondamentale per rendere efficiente il funzionamento dei link: una volta ottenuto l’indirizzo IP di un dominio, il resolver lo memorizza per un periodo stabilito dal valore TTL (Time To Live) del dominio. Grazie a questa cache non serve ripetere una ricerca DNS completa ogni volta che qualcuno visita un sito, velocizzando il collegamento. Anche il browser e gli ISP mantengono una loro cache DNS, così come altri resolver in rete. Questo sistema a più livelli assicura che i siti più popolari siano accessibili rapidamente, senza dover interrogare ogni volta i nameserver autorevoli.
Sii il primo a conoscere le nuove funzionalità e gli aggiornamenti del prodotto.
Il protocollo specificato all’inizio di un URL determina come il browser comunica con il server web. HTTP (Hypertext Transfer Protocol) era il protocollo originale per la comunicazione web, ma trasmetteva i dati in chiaro, senza crittografia; ciò significava che chiunque intercettasse il traffico poteva leggere dati sensibili come password o carte di credito. HTTPS (Hypertext Transfer Protocol Secure) risolve questa vulnerabilità aggiungendo uno strato di crittografia tramite certificati SSL/TLS (Secure Sockets Layer/Transport Layer Security).
Quando visiti un sito HTTPS, il browser e il server eseguono un handshake TLS per stabilire una connessione criptata. Durante questa fase, il server presenta un certificato digitale che prova la sua identità e contiene una chiave pubblica. Il browser verifica l’autenticità del certificato confrontandolo con una lista di Certificate Authorities di fiducia. Una volta verificato, browser e server usano la chiave pubblica per stabilire una chiave di cifratura condivisa, che viene impiegata per criptare tutte le comunicazioni successive. Così, anche se il traffico di rete viene intercettato, i dati trasmessi restano illeggibili.
La differenza tra HTTP e HTTPS non riguarda solo la sicurezza, ma anche il posizionamento sui motori di ricerca e la fiducia degli utenti. Google e altri motori di ricerca danno la preferenza nei risultati ai siti HTTPS e i browser moderni mostrano avvisi quando un utente visita siti HTTP. Gli utenti hanno imparato a cercare il lucchetto nella barra degli indirizzi come segnale di sicurezza, e spesso abbandonano un sito se vedono avvisi di sicurezza. Per questi motivi, HTTPS è diventato lo standard per tutti i siti, non solo quelli che trattano informazioni sensibili.
I parametri URL, o query string, permettono ai siti di passare informazioni aggiuntive al server tramite l’URL stesso. Questi parametri compaiono dopo il punto interrogativo (?) nell’URL e sono costituiti da coppie chiave-valore separate da una e commerciale (&). Ad esempio, un URL di ricerca potrà essere https://www.example.com/search?q=link+siti+web&category=tecnologia&sort=rilevanza. Ogni parametro fornisce informazioni specifiche che il server usa per personalizzare la risposta.
I parametri URL svolgono molte funzioni importanti nel funzionamento dei link. I motori di ricerca li usano per tracciare le query e filtrare i risultati. I siti e-commerce li impiegano per filtrare prodotti per categoria, fascia di prezzo o altre caratteristiche. Le piattaforme di analisi usano i parametri UTM per tracciare la provenienza e l’efficacia delle campagne di marketing. I parametri per la paginazione consentono di suddividere grandi quantità di dati su più pagine. Senza i parametri URL, i siti sarebbero molto meno flessibili e potenti, incapaci di personalizzare i contenuti o tracciare efficacemente il comportamento degli utenti.
Tuttavia i parametri URL pongono anche sfide per la SEO e l’esperienza utente: i motori di ricerca possono considerare URL con parametri diversi come pagine distinte, creando problemi di contenuto duplicato. URL molto lunghi possono essere difficili da leggere e condividere. Per questi motivi nelle pratiche moderne si preferiscono, quando possibile, strutture più pulite usando i percorsi invece dei parametri (ad esempio, example.com/products/shoes invece di example.com/products?category=shoes). Tuttavia, i parametri rimangono indispensabili per contenuti dinamici e per il tracciamento.
Capire come funzionano i link significa anche conoscere ciò che può andare storto. L’errore più comune è il 404 Not Found, che si verifica quando il server non trova la risorsa richiesta all’URL specificato. Ciò può succedere se una pagina è stata cancellata, spostata o se c’è un errore di battitura nell’URL. Altri errori frequenti sono il 403 Forbidden (quando non hai i permessi di accesso), il 500 Internal Server Error (errore interno del server) o il 502 Bad Gateway (risposta non valida da un server a monte).
Quando incontri un link interrotto, puoi seguire alcuni passaggi: controlla attentamente l’URL per errori di battitura o maiuscole errate (gli URL sono case-sensitive: Example.com e example.com possono essere considerati diversi). Se l’URL sembra corretto, prova a rimuovere il percorso dopo il nome dominio per vedere se la home del sito è accessibile. Se la home funziona ma la pagina specifica no, probabilmente è stata spostata o cancellata; prova a cercare il contenuto tramite un motore di ricerca, potresti trovare l’URL aggiornato o una versione archiviata.
I proprietari di siti possono prevenire i link rotti implementando redirect adeguati quando gli URL cambiano. Un redirect 301 (reindirizzamento permanente) segnala a browser e motori di ricerca che una pagina è stata spostata definitivamente, preservando il posizionamento e reindirizzando automaticamente gli utenti. Un redirect 302 (temporaneo) indica uno spostamento temporaneo e non trasferisce l’autorità SEO. Impiegando i redirect in modo strategico, si mantiene una buona esperienza utente e il posizionamento anche durante la ristrutturazione del sito.
Creare URL efficaci richiede la comprensione del loro funzionamento e la considerazione sia di fattori tecnici che di usabilità. Gli URL dovrebbero essere descrittivi e includere parole chiave rilevanti che indicano il contenuto della pagina. Ad esempio, example.com/blog/come-ottimizzare-link-siti-web è molto più informativo di example.com/page123. URL descrittivi aiutano utenti e motori di ricerca a capire cosa aspettarsi dal contenuto, migliorando il tasso di clic e la condivisione sui social.
Gli URL dovrebbero essere il più corti possibile, pur restando descrittivi. URL lunghi sono difficili da digitare, ricordare e condividere. Possono anche essere troncati nei risultati di ricerca o nei post social, riducendo la loro efficacia. È meglio usare il trattino per separare le parole, poiché i motori di ricerca lo interpretano come separatore, mentre l’underscore non sempre viene riconosciuto. Utilizza lettere minuscole in modo coerente, poiché alcuni server distinguono tra maiuscole e minuscole.
La struttura degli URL dovrebbe riflettere l’organizzazione logica dei contenuti del sito. Una struttura gerarchica come example.com/products/elettronica/notebook/gaming indica chiaramente la relazione tra le sezioni e aiuta gli utenti a orientarsi. Questa struttura facilita anche la scansione e l’indicizzazione da parte dei motori di ricerca. Nella pianificazione della struttura degli URL, pensa a come il sito potrà crescere ed evolversi, progettando URL che rimangano pertinenti e funzionali nel tempo.
I frammenti URL, indicati dal cancelletto (#) seguito da un identificatore, permettono ai link di puntare a sezioni specifiche di una pagina. Ad esempio, example.com/articolo#sezione-2 fa sì che il browser apra la pagina e scorra automaticamente alla sezione con l’ID “sezione-2”. I frammenti vengono gestiti completamente dal browser lato client e non vengono inviati al server, rendendoli utili per migliorare l’esperienza utente senza elaborazione lato server. Molti siti moderni usano ampiamente i frammenti per creare esperienze fluide in applicazioni a pagina singola.
I link ancora, creati tramite tag HTML con attributo ID, funzionano assieme ai frammenti per consentire una navigazione precisa all’interno delle pagine. Quando un utente clicca su un link ancora o visita un URL con frammento, il browser scorre automaticamente fino all’elemento corrispondente. Questa funzionalità è particolarmente preziosa per contenuti lunghi come articoli o guide, dove l’utente può voler saltare direttamente a una sezione. Anche i motori di ricerca riconoscono e indicizzano questi link, permettendo di mostrare collegamenti diretti a sezioni specifiche dei risultati, migliorando CTR e soddisfazione dell’utente.
Il deep linking consiste nel collegare direttamente contenuti specifici di un sito invece della sola homepage. I deep link sono fondamentali per la user experience e la SEO, poiché permettono agli utenti di accedere subito al contenuto desiderato senza navigare tra più pagine. I motori di ricerca premiano i siti che adottano buone pratiche di deep linking, segno di un’architettura informativa ben organizzata. Per affiliate marketer e content creator, il deep linking è particolarmente importante in quanto consente di indirizzare il traffico verso prodotti, articoli o risorse più rilevanti per il proprio pubblico.
Per i marketer affiliati, capire come funzionano i link è fondamentale per la gestione efficace delle campagne e il monitoraggio delle performance. I link affiliati sono URL speciali che includono parametri di tracciamento che identificano l’affiliato, la campagna e altre informazioni rilevanti. Quando un utente clicca su un link affiliato e completa un acquisto o un’azione desiderata, i parametri permettono alla rete di attribuire la conversione all’affiliato e alla campagna corretti. Questa attribuzione è essenziale per calcolare le commissioni e misurare le performance delle campagne.
PostAffiliatePro, la principale piattaforma software di affiliazione, offre strumenti avanzati per la creazione, gestione e tracciamento dei link affiliati. La piattaforma permette agli affiliati di generare link personalizzati con parametri di tracciamento integrati, monitorare in tempo reale click e conversioni e ottimizzare le campagne sulla base di analisi dettagliate. Il sistema di gestione link di PostAffiliatePro garantisce tracciamento accurato su più canali e dispositivi, fornendo agli affiliati i dati necessari a massimizzare i guadagni. Le funzioni di abbreviazione degli URL rendono i link più condivisibili sui social, mantenendo però tutte le capacità di tracciamento.
Comprendere la struttura e i parametri degli URL è particolarmente importante per chi usa PostAffiliatePro. La piattaforma consente di personalizzare i parametri di tracciamento per raccogliere informazioni specifiche sulle fonti di traffico, sulle campagne e sul comportamento degli utenti. Usando strategicamente i parametri URL, gli affiliati possono segmentare il traffico e identificare quali campagne e canali sono più redditizi. Questo approccio data-driven consente l’ottimizzazione continua delle performance delle campagne, portando a guadagni più elevati e a un miglior ritorno sull’investimento.
Diventa esperto nella gestione e nel tracciamento dei link con il software di affiliazione leader del settore. PostAffiliatePro offre tracciamento avanzato degli URL, gestione dei link e analisi dettagliate per massimizzare le performance del tuo marketing di affiliazione.
Scopri perché i link sono fondamentali per il successo di un sito web. Impara come i link interni ed esterni migliorano la SEO, l’esperienza utente e la scansio...
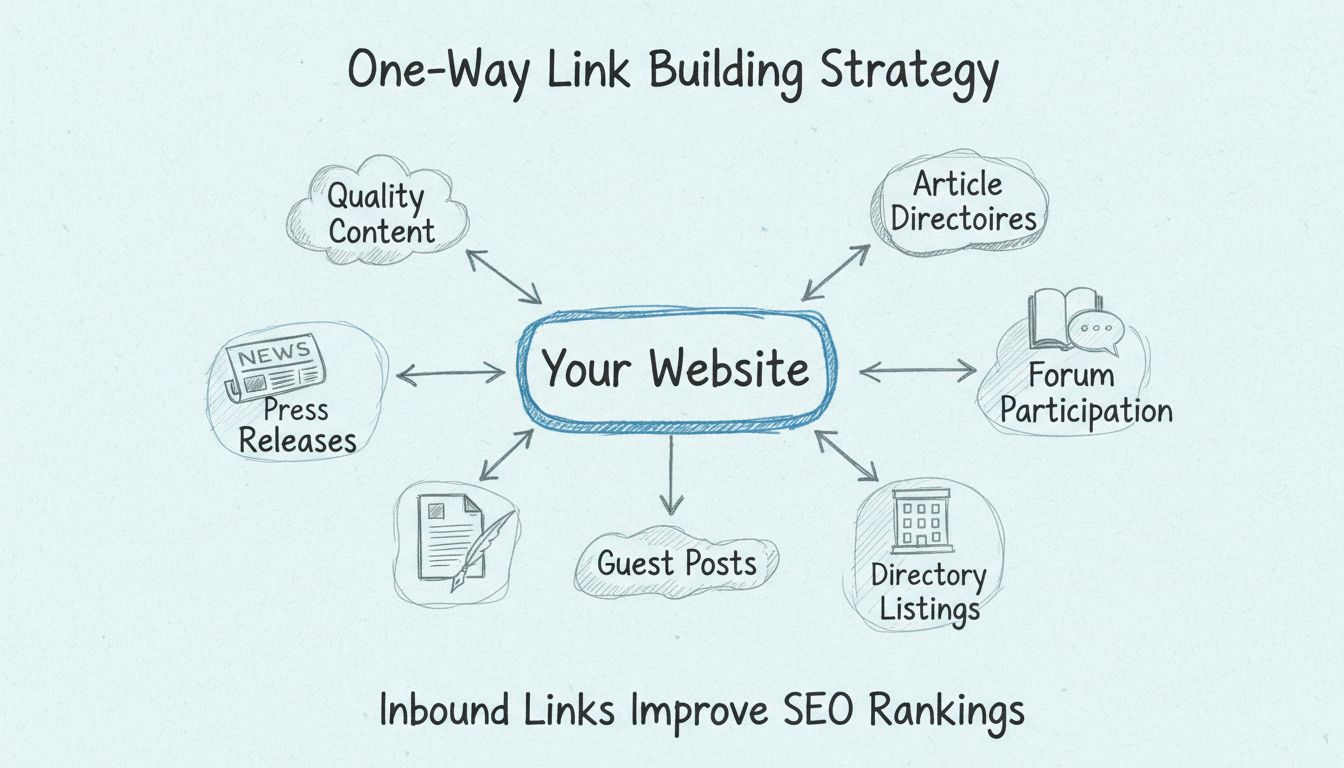
Scopri strategie comprovate per ottenere link a senso unico tramite contenuti di qualità, directory di articoli, comunicati stampa e partecipazione ai forum. Sc...

Guida completa ai diversi tipi di link tra cui link interni, link esterni, backlink, link attivi, link inattivi, dofollow, nofollow e altro. Scopri come ogni ti...
Unisciti alla nostra community di clienti soddisfatti e fornisci un eccellente supporto clienti con PostAffiliatePro.
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.