
Come Funzionano i Web Crawler? Guida Tecnica Completa
Scopri come funzionano i web crawler, dagli URL seed all'indicizzazione. Comprendi il processo tecnico, i tipi di crawler, le regole del robots.txt e come i cra...
10 min di lettura
I crawler, noti anche come spider o bot, navigano e indicizzano sistematicamente Internet, consentendo ai motori di ricerca di comprendere e classificare le pagine web per query pertinenti.
I crawler, noti anche come spider o bot, sono sofisticati programmi software automatizzati progettati per navigare e indicizzare sistematicamente la vasta distesa di Internet. La loro funzione principale è aiutare i motori di ricerca a comprendere, categorizzare e classificare le pagine web in base alla loro rilevanza e ai loro contenuti. Questo processo è fondamentale affinché i motori di ricerca forniscano risultati accurati agli utenti. Scansionando continuamente le pagine web, i crawler costruiscono un indice completo che motori come Google utilizzano per offrire risultati di ricerca precisi e pertinenti.
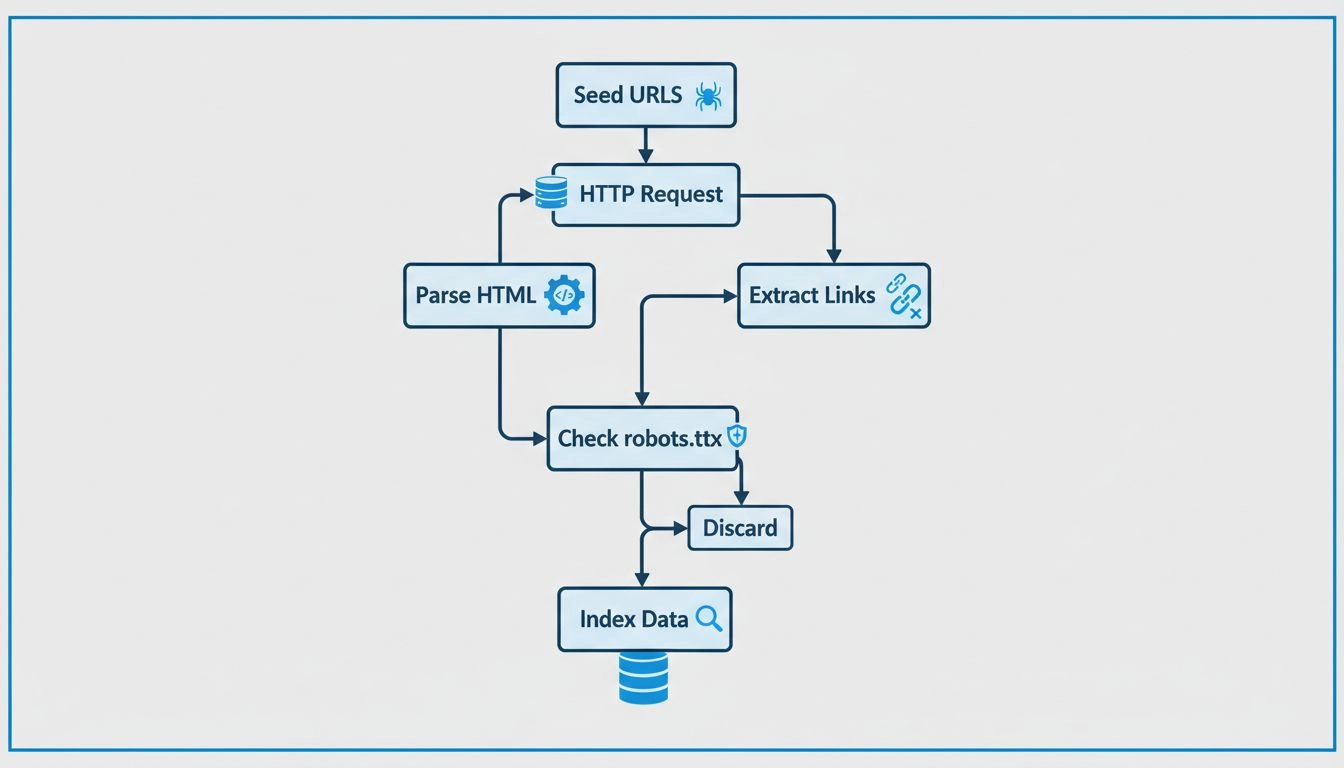
I web crawler sono essenzialmente gli occhi e le orecchie dei motori di ricerca, permettendo loro di vedere cosa c’è su ogni pagina web, comprenderne il contenuto e decidere dove inserirla nell’indice. Iniziano con un elenco di URL conosciuti e lavorano metodicamente su ogni pagina, analizzando i contenuti, identificando i link e aggiungendoli alla loro coda per future scansioni. Questo processo iterativo consente ai crawler di mappare la struttura dell’intero web, proprio come un bibliotecario digitale che cataloga libri.
Configura il tracciamento avanzato in pochi minuti. Nessuna carta di credito richiesta.
I crawler operano iniziando con una lista di URL di partenza, che visitano e ispezionano. Durante la scansione di queste pagine web, identificano i link verso altre pagine, aggiungendoli alla coda per la scansione successiva. Questo processo permette loro di mappare la struttura del web, seguendo i collegamenti da una pagina all’altra, proprio come un bibliotecario digitale che organizza i libri. Il contenuto di ciascuna pagina, inclusi testo, immagini e meta tag, viene analizzato e archiviato in un enorme indice. Questo indice rappresenta la base su cui i motori di ricerca recuperano informazioni pertinenti in risposta alle query degli utenti.
I web crawler consultano il file robots.txt di ogni pagina che visitano. Questo file fornisce regole che indicano quali pagine devono essere scansionate e quali ignorate. Dopo aver controllato queste regole, i crawler procedono a navigare la pagina seguendo i collegamenti ipertestuali secondo politiche predefinite, come il numero di link che puntano a una pagina o l’autorevolezza della pagina stessa. Queste politiche aiutano a dare priorità alle pagine da scansionare per prime, garantendo che quelle più importanti o rilevanti vengano indicizzate tempestivamente.
Durante la scansione, questi bot memorizzano i contenuti e i metadati di ciascuna pagina. Queste informazioni sono fondamentali per i motori di ricerca nella determinazione della rilevanza di una pagina rispetto a una query utente. I dati raccolti vengono poi indicizzati, permettendo al motore di ricerca di recuperare e classificare rapidamente le pagine quando viene effettuata una ricerca.
Per affiliate marketer , comprendere il funzionamento dei crawler è essenziale per ottimizzare i propri siti web e migliorare il posizionamento sui motori di ricerca. Un’efficace strategia SEO prevede la strutturazione dei contenuti in modo che siano facilmente accessibili e comprensibili da questi bot. Le pratiche SEO fondamentali includono:
Sii il primo a conoscere le nuove funzionalità e gli aggiornamenti del prodotto.
Nel contesto dell’affiliate marketing , i crawler hanno un ruolo particolare. Ecco alcune considerazioni chiave:
I marketer affiliati possono utilizzare strumenti come Google Search Console per ottenere informazioni su come i crawler interagiscono con i loro siti. Questi strumenti forniscono dati su errori di scansione, invio di sitemap e altre metriche, consentendo ai marketer di migliorare la scansione e l’indicizzazione del sito. Il monitoraggio dell’attività dei crawler aiuta a individuare problemi che possono ostacolare l’indicizzazione, permettendo correzioni tempestive.
I contenuti indicizzati sono fondamentali per la visibilità nei risultati dei motori di ricerca. Senza indicizzazione, una pagina web non comparirà nei risultati di ricerca, indipendentemente dalla sua pertinenza rispetto a una query. Per gli affiliati , garantire che i loro contenuti vengano indicizzati è cruciale per generare traffico organico e tassi di conversione. Una corretta indicizzazione assicura che i contenuti possano essere scoperti e posizionati adeguatamente.
La SEO tecnica consiste nell’ottimizzare l’infrastruttura del sito per facilitare una scansione e un’indicizzazione efficienti. Ciò include:
Dati strutturati: Implementare dati strutturati aiuta i crawler a comprendere il contesto dei contenuti, migliorando le possibilità del sito di apparire nei risultati di ricerca avanzati. I dati strutturati forniscono informazioni aggiuntive che possono aumentare la visibilità nei motori di ricerca.
Velocità e prestazioni del sito: I siti che si caricano rapidamente sono preferiti dai crawler e contribuiscono a un’esperienza utente positiva. Un sito più veloce può portare a un miglior posizionamento e a un aumento del traffico.
Pagine senza errori: Individuare e correggere gli errori di scansione garantisce che tutte le pagine importanti siano accessibili e indicizzabili. Audit regolari aiutano a mantenere la salute del sito e migliorare le performance SEO.

I crawler dei motori di ricerca possono essere identificati in diversi modi, tra cui esaminando lo user-agent, controllando l'indirizzo IP del crawler e cercando modelli negli header delle richieste.
I web crawler lavorano inviando richieste ai siti web e poi seguendo i link presenti su questi siti verso altri siti. Tengono traccia delle pagine che visitano e dei link che trovano per poter indicizzare il web e renderlo ricercabile.
I web crawler sono chiamati spider perché 'strisciano' attraverso il web, seguendo i collegamenti da una pagina all'altra.
Scopri come comprendere e ottimizzare per i crawler può aumentare la visibilità del tuo sito web e il posizionamento sui motori di ricerca.
Scopri come funzionano i web crawler, dagli URL seed all'indicizzazione. Comprendi il processo tecnico, i tipi di crawler, le regole del robots.txt e come i cra...
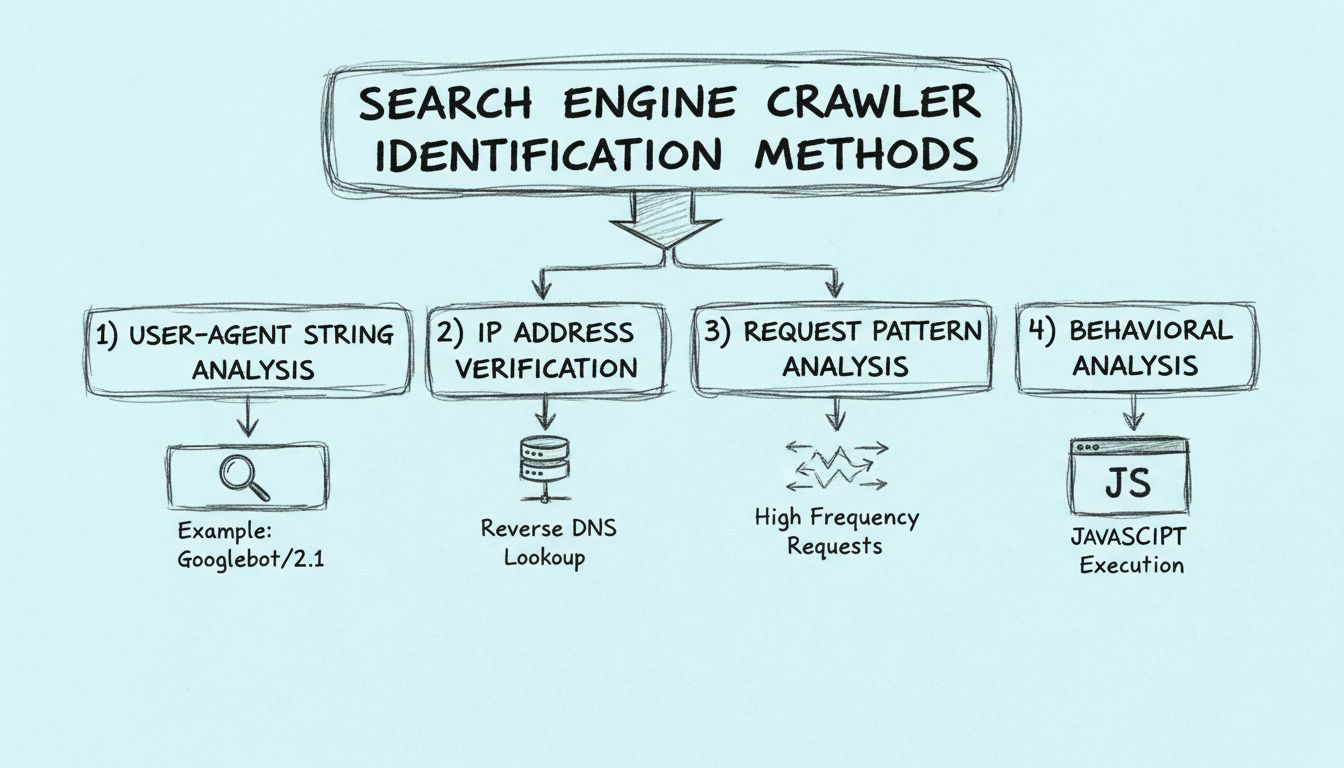
Scopri come identificare i crawler dei motori di ricerca utilizzando stringhe user-agent, indirizzi IP, pattern di richiesta e analisi comportamentale. Guida es...
Gli spider sono bot creati per lo spamming, che possono causare molti problemi alla tua attività. Scopri di più su di loro nell'articolo.
Unisciti alla nostra community di clienti soddisfatti e fornisci un eccellente supporto clienti con PostAffiliatePro.
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.